Join the Menttor community
Access accelerated AI inference, track progress, and collaborate on roadmaps with students worldwide.
Attention Is All You Need
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30.
Read Original Paper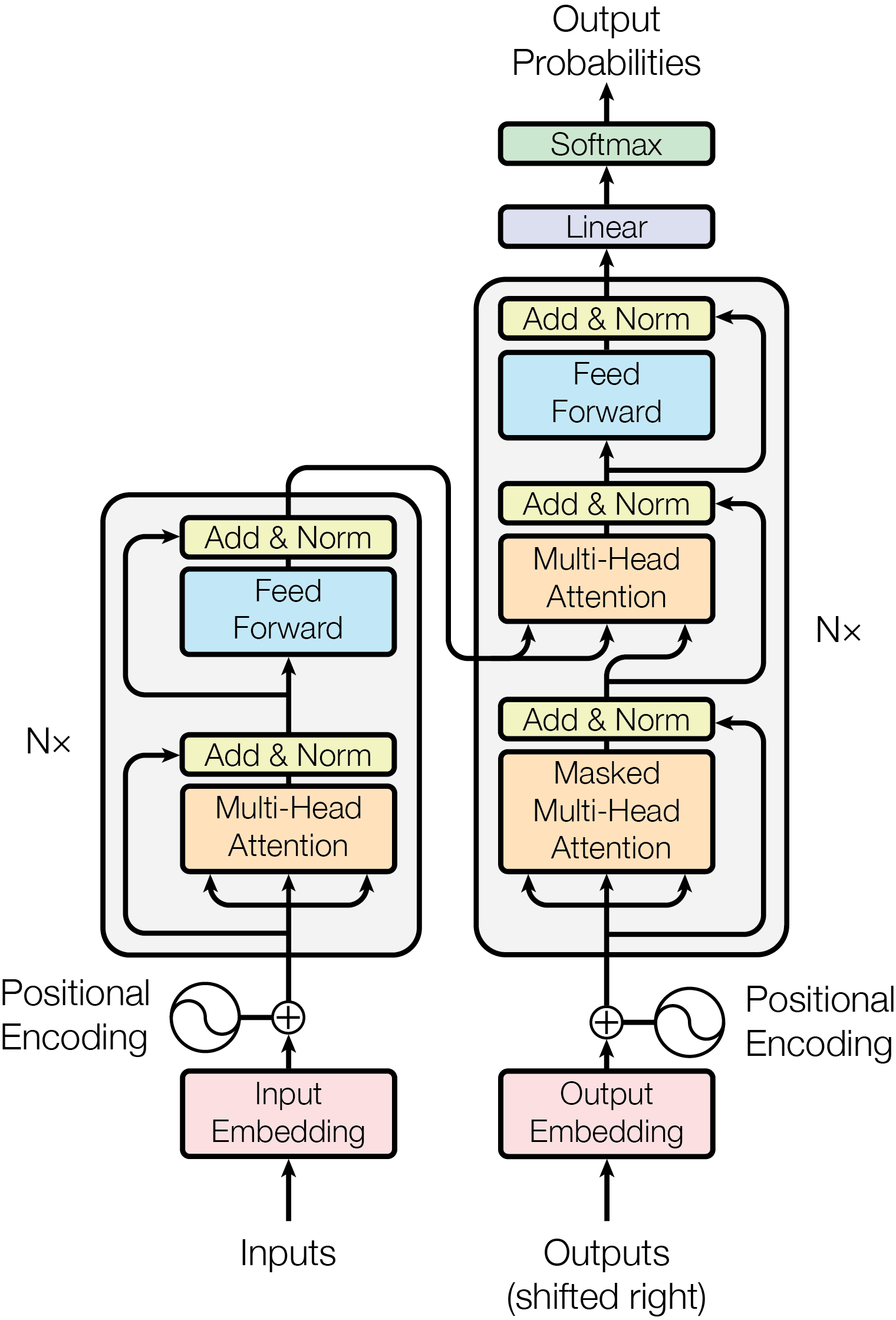
A re-reading of the 2017 paper from Google Research, 'Attention Is All You Need', reveals how much the current technological landscape relies on a single observation: that sequence modeling does not actually require a sequence. For years, language was processed as a timeline, one word after another, moving from left to right. Recurrent networks were used that had to store what happened many steps ago to understand the present. It was a slow, fragile approach, and the researchers at Google effectively argued that it could be discarded entirely.
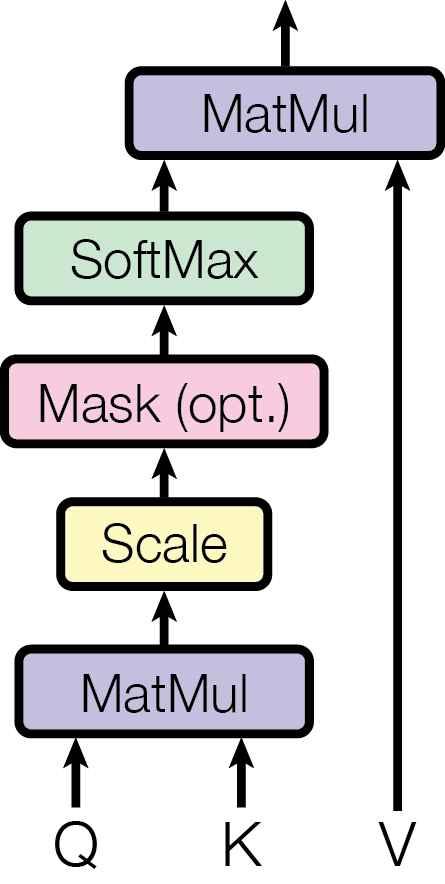
Scaled Dot-Product Attention
Multi-Head Attention mechanism allowing the model to attend to information from different representation subspaces.
The fundamental technical shift in the Transformer was the use of Scaled Dot-Product Attention as the sole mechanism for capturing relationships between words. The formula calculates attention scores by taking the dot product of a Query (Q) and a Key (K), then scaling the result by the square root of the dimension dk. This scaling factor is critical; without it, the dot products for large dimensions grow so large that the softmax function enters regions with extremely small gradients, preventing the model from learning. By normalizing the signal, the researchers ensured that the attention mechanism remains stable even as the model scales. This proved that the most effective way to process information is not through sequential memory, but through a global, parallelized comparison of every unit of data against every other unit. It revealed that 'meaning' is a spatial relationship between tokens rather than a temporal one.
Multi-Head Attention Subspaces
How the Transformer achieves a nuanced understanding of language lies in its use of Multi-Head Attention. Instead of a single attention function, the model performs multiple attention operations in parallel, each focusing on different 'representation subspaces.' For example, one head might focus on grammatical relationships while another captures semantic context. By projecting the Queries, Keys, and Values into these different spaces before calculating attention, the model can jointly attend to diverse information at different positions. This finding revealed that intelligence is not a monolithic signal but an ensemble of parallel perspectives. It suggested that the most powerful architectures are those that can look at the same data through multiple lenses simultaneously, capturing the web of relationships that define human language.
Positional Encodings
Because the Transformer processes the entire sequence in parallel, it inherently lacks a sense of word order. The technical solution was the injection of 'positional encodings' using sine and cosine functions of different frequencies. These specific sinusoidal functions were chosen because they allow the model to easily learn to attend by relative positions—for any fixed offset k, the encoding at position pos+k can be represented as a linear function of the encoding at position pos. This approach allowed the model to maintain the flexibility of a parallel architecture while regaining the necessary structure of a sequence. It proved that the concept of 'time' or 'order' in data can be mathematically encoded as a static signal rather than a dynamic process. This revealed that the bottleneck in AI was often the assumption that machines must process data in the same sequential way that humans do.
Encoder-Decoder Context
A final technical detail is the specific structure of the encoder-decoder attention sub-layer. In this layer, the Queries come from the previous decoder layer, while the Keys and Values come from the output of the encoder. This configuration allows every position in the decoder to attend over all positions in the original input sequence, effectively allowing the generator to 'consult' the entire source context while producing each token. This proved that the most effective way to translate or summarize data is to maintain a constant, high-fidelity link to the original information. It suggested that progress in artificial intelligence is often less about finding more sophisticated ways to think and more about finding ways to let hardware perform more parallel work simultaneously while maintaining a global context.
Dive Deeper
Illustrated Transformer
Jay Alammar • article
Explore ResourceAttention Is All You Need Paper
arXiv • article
Explore Resource