Join the Menttor community
Access accelerated AI inference, track progress, and collaborate on roadmaps with students worldwide.
Flamingo: Visual Language Few-Shot
Alayrac, J. B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y., ... & Zisserman, A. (2022). Flamingo: a visual language model for few-shot learning. Advances in Neural Information Processing Systems, 35, 23716-27744.
Read Original Paper
The 2022 paper on Flamingo introduced a family of visual language models (VLMs) that could adapt to new tasks with only a few examples, similar to the capabilities of large language models like GPT-3. For years, vision-language systems required massive task-specific fine-tuning. Researchers at DeepMind proposed an architecture that bridges a powerful, frozen vision encoder with a large, frozen language model. It was a shift toward viewing multimodality as an interleaved sequence of visual and textual information.
Gated Cross-Attention
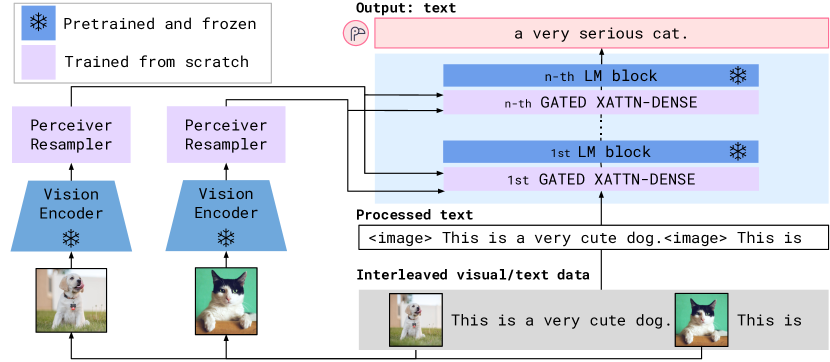
Flamingo architecture overview: visual features are fused into a frozen language model via cross-attention.
The technical shift was the introduction of 'gated cross-attention' layers that connect the vision and language components. By inserting these layers between the pre-trained blocks of a language model, Flamingo learns to incorporate visual information without forgetting its language capabilities. As the authors put it, 'Flamingo models are trained on a large-scale mixture of web-scraped image-text pairs and video-text pairs... providing the models with the ability to handle a wide range of tasks.' This modular approach allows for rapid adaptation to diverse visual reasoning tasks through simple prompting.
Perceiver Resampler
The reasoning behind Flamingo was the need to handle visual data of varying resolutions and lengths, such as videos or multiple images in a dialogue. They introduced the 'Perceiver Resampler,' which maps a variable number of visual features to a fixed set of visual tokens. This revealed that the bottleneck in multimodal AI is often the interface between different data types. By creating a uniform representation for vision, Flamingo can process complex, interleaved sequences as easily as text.
Few-Shot Visual Reasoning
The success of Flamingo proved that 'in-context learning' is not limited to text. By providing a few (image, text) pairs in the prompt, the model can solve novel visual tasks without any weight updates. This suggests that the future of vision is not just about recognition, but about reasoning within a semantic context. It raises the question of how we can continue to scale these multimodal Generalists to handle the full complexity of human experience.
Dive Deeper
DeepMind Flamingo Blog
DeepMind • article
Explore ResourceFlamingo Paper on arXiv
arXiv • article
Explore Resource