Join the Menttor community
Access accelerated AI inference, track progress, and collaborate on roadmaps with students worldwide.
CLIP: Contrastive Language-Image Pre-training
Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., ... & Sutskever, I. (2021). Learning transferable visual models from natural language supervision. In International conference on machine learning (pp. 8748-8763). PMLR.
Read Original Paper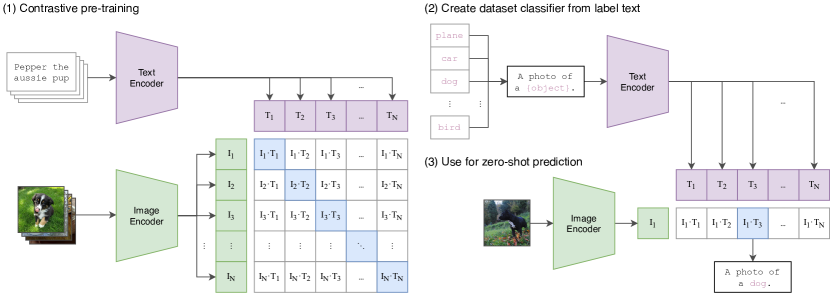
The 2021 CLIP (Contrastive Language-Image Pre-training) paper by OpenAI marked a fundamental shift in computer vision by moving from fixed category labels to the fluid context of natural language. For decades, vision models were restricted to discrete sets of labels—a model trained on ImageNet could identify a 'Golden Retriever' but lacked the conceptual flexibility to understand 'a happy dog playing in a park.' Researchers at OpenAI proposed that vision and language should be learned as a single, shared representation, allowing a model to understand images through the same open-ended concepts humans use to describe them. It was a shift toward 'open-vocabulary' vision, suggesting that the most powerful way to see the world is through the lens of everything we have ever written about it.
Contrastive Pre-training at Scale
CLIP jointly trains an image encoder and a text encoder to predict correct image-text pairings.
The technical shift in CLIP was the use of a contrastive learning objective on a massive dataset of 400 million image-text pairs scraped from the internet. Instead of being trained to predict a specific class, the model is trained to identify which text snippet correctly matches which image within a large batch of possibilities. This 'dual-encoder' architecture—one for images and one for text—forces the system to map both modalities into a single, shared embedding space where similar concepts are mathematically close to each other regardless of their source. It proved that the 'meaning' of an image can be captured by its relationship to human language, effectively turning the entire internet into a teacher for a new kind of visual common sense.
Zero-Shot Transfer and Prompting
The reasoning behind CLIP was to create a model that could perform tasks it was never explicitly trained for, a capability known as zero-shot transfer. Because the model understands language, it can be 'instructed' to perform new classification tasks at test time by simply providing it with the names of the target classes. By wrapping these names in a natural language prompt—such as 'a photo of a {label}'—the model can leverage its pre-trained understanding of sentence structure to improve its accuracy. This demonstrated that a model's utility is not limited by its training labels, but by the breadth of the concepts it has encountered. It revealed that the bottleneck in AI was often the rigidity of our interfaces, and that natural language is the most flexible tool we have for guiding artificial intelligence.
Closing the Robustness Gap
One of the most significant findings was CLIP's remarkable robustness to distribution shift, maintaining high performance on images that are radically different from standard datasets, such as sketches, cartoons, or distorted photos. While traditional models are often fragile and easily fooled by these variations, CLIP's language-based training provides a more generalized and resilient understanding of the world. This resilience suggests that by learning from the rich context of human speech, the model has captured the 'essence' of concepts rather than just the raw pixel patterns that define a specific dataset. It raises the question of whether 'meaning' in vision is best understood as a purely visual property or as a reflection of the symbolic labels we have assigned to the world.
Dive Deeper
OpenAI CLIP Blog
OpenAI • article
Explore ResourceCLIP on GitHub
GitHub • code
Explore Resource