Join the Menttor community
Access accelerated AI inference, track progress, and collaborate on roadmaps with students worldwide.
QLoRA: Efficient Fine-tuning
Dettmers, T., Pagnoni, A., Holtzman, A., & Zettlemoyer, L. (2023). QLoRA: Efficient Finetuning of Quantized LLMs. arXiv:2305.14314.
Read Original Paper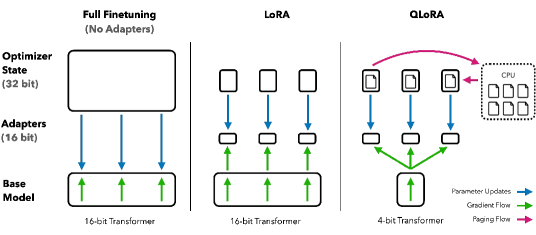
The 2023 paper on 'QLoRA' (Quantized Low-Rank Adaptation) fundamentally changed the economics of artificial intelligence by democratizing the ability to fine-tune massive language models. Before QLoRA, training a 65-billion parameter model like LLaMA required over 780 gigabytes of VRAM—a requirement that limited the field to massive, multi-GPU clusters owned by a few tech giants. Researchers at the University of Washington proposed a shift: instead of training on 16-bit weights, they developed a system to fine-tune 4-bit quantized models without any loss in performance. This transition allowed a 65B model to be fine-tuned on a single professional GPU, proving that the high precision of a model's 'memory' is not necessary for its 'learning,' much like a student can learn from a summary just as well as from a full textbook.
The 4-bit NormalFloat Shift
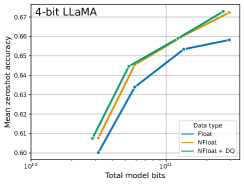
Performance of 4-bit NormalFloat compared to standard quantization data types.
The core technical shift in QLoRA was the introduction of the 4-bit NormalFloat (NF4) data type, which shapes the model's storage to fit the actual data. Unlike standard compression that uses even mathematical buckets, NF4 is designed to be information-theoretically optimal for the normal distribution of weights found in neural networks. By using quantile quantization, the researchers ensured that each of the 16 possible values in a 4-bit bin carries the maximum amount of information. This approach revealed that the 'storage' of a model's knowledge can be extremely compressed without losing its 'utility.' It proved that the fidelity of the base model can be reduced to just 4 bits as long as the learning process itself—the adapters—remains in higher 16-bit precision. This finding suggested that the most effective way to store intelligence is not through uniform precision but through a data-aware compression that prioritizes the most frequent weight values.
Double Quantization and Paged Memory

The memory footprint of different LLaMA models under the QLoRA framework.
How QLoRA achieves its massive memory reduction lies in two specific engineering breakthroughs: Double Quantization and Paged Optimizers. Double Quantization treats the 'scaling constants' of the first round of quantization as data themselves, quantizing them a second time to save an additional 3 gigabytes of VRAM on a 65B model. Simultaneously, Paged Optimizers act like a pressure-relief valve, automatically moving data from the GPU to the CPU RAM when memory usage spikes. This revealed that memory management in AI is not a static limit but a dynamic process that can be managed through clever paging. By turning the GPU's memory into a rolling buffer of gradients, the researchers proved that hardware constraints are often just software bottlenecks in disguise, proving that the efficiency of an algorithm is as important as the raw power of the chip.
The Democratization of Scale
The success of QLoRA was most evident in the performance of the 'Guanaco' models, where a 65-billion parameter model fine-tuned on a single GPU reached 99.3% of the performance of ChatGPT. This finding revealed that the barrier to state-of-the-art AI is not the cost of the hardware, but the efficiency of the software. It proved that the 'efficiency frontier' of fine-tuning is far lower than the industry had assumed, allowing independent researchers with a single GPU to compete with those using hundreds. This raises the question of whether the next leap in AI will come from larger models or from a deeper integration of these quantization techniques into every stage of the model lifecycle. It suggested that in the future, the most powerful models will not be the ones that use the most memory, but the ones that use it most surgically to maintain their learning capacity.
Dive Deeper
QLoRA Paper on arXiv
arXiv • article
Explore ResourceGitHub Implementation
GitHub • code
Explore ResourceHugging Face Blog
Hugging Face • article
Explore Resource