Join the Menttor community
Access accelerated AI inference, track progress, and collaborate on roadmaps with students worldwide.
Stable Diffusion: Latent Space
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., & Ommer, B. (2022). High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 10684-10695).
Read Original Paper
In 2021, the release of Latent Diffusion Models, later known as Stable Diffusion, solved the problem of computational cost in generative AI. While earlier diffusion models worked directly on image pixels, they were incredibly slow and resource-heavy. Researchers at LMU Munich and Runway proposed that generation should instead happen in a 'latent space'—a compressed mathematical representation of an image. It was a push to make high-quality generation accessible on consumer hardware by separating the act of creation from the act of rendering.
Diffusion in Latent Space
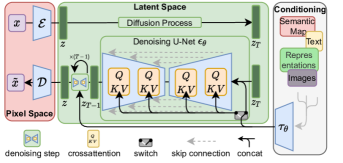
Latent Diffusion architecture showing the interaction between the autoencoder, the U-Net, and the conditioning mechanism.
The technical shift was the use of an autoencoder to compress images into a smaller, more manageable space before applying the diffusion process. By removing imperceptible details and focusing only on the semantic essence of an image, the model can operate much more efficiently. As the authors stated, 'By decomposing the image formation process into a sequence of denoising autoencoders, diffusion models (DMs) achieve state-of-the-art synthesis results... we show that they can also be applied in the latent space of pre-trained autoencoders.' This allows for high-resolution synthesis without the need for massive computing clusters.
Universal Conditioning
The reasoning behind Stable Diffusion was the need for a more flexible way to guide the generative process. They introduced a 'cross-attention' mechanism that allows the model to be conditioned on various inputs, such as text, depth maps, or other images. This turned the diffusion model into a universal generative engine that can follow complex instructions. It revealed that generation is most powerful when it can be steered by human concepts, rather than just random noise.
The Efficiency Shift
The success of Stable Diffusion marked a shift in the AI industry toward efficiency and democratization. By proving that high-performance models could run on standard GPUs, the researchers catalyzed a wave of open-source innovation. This revealed that the most impactful breakthroughs are often the ones that reduce the barriers to entry. It raises the question of whether the future of AI will be defined by the size of the models or by the cleverness of the compression that makes them usable by everyone.
Dive Deeper
Stable Diffusion Blog
Stability AI • article
Explore ResourceLDM Paper on GitHub
GitHub • code
Explore Resource