Join the Menttor community
Access accelerated AI inference, track progress, and collaborate on roadmaps with students worldwide.
GPT-4 Technical Report
OpenAI. (2023). GPT-4 Technical Report. arXiv preprint arXiv:2303.08774.
Read Original Paper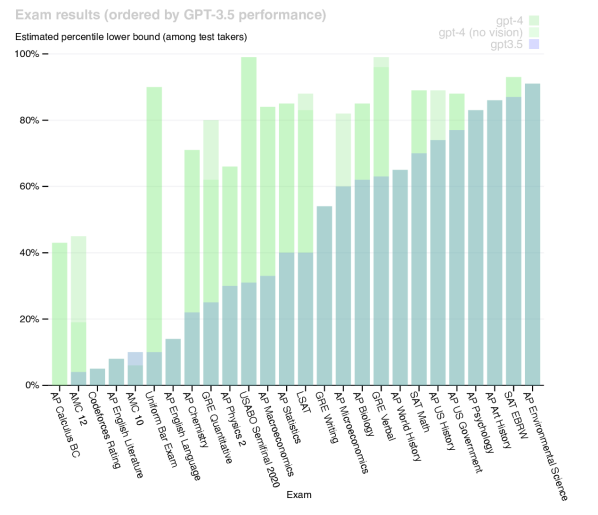
The release of the GPT-4 Technical Report in 2023 marked a transition from the era of experimental large language models to a period of predictable engineering. Before GPT-4, the development of massive neural networks was often characterized by uncertainty, where the final performance of a model was only known after millions of dollars in compute had already been spent. OpenAI's researchers demonstrated that this unpredictability is not an inherent property of AI. By training much smaller models—miniature versions of the final architecture—they found that the mathematical loss followed a clear, measurable curve. It was a shift that suggested intelligence is not a random byproduct of scale but a quantifiable trajectory that can be mapped before the first watt of power is used for the full-scale run.
Predictable Scaling Laws
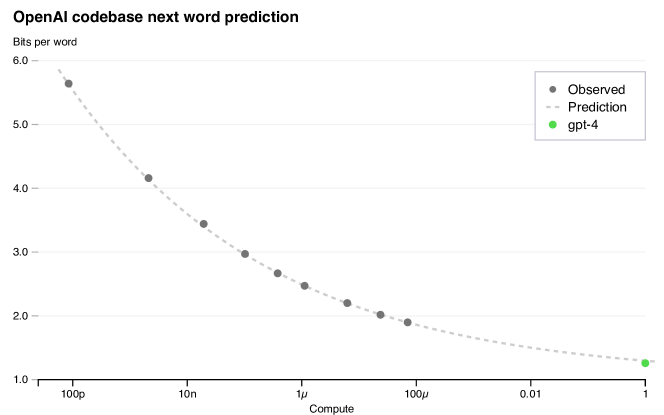
Predicting the final loss of GPT-4 using smaller models and a power law fit.
The fundamental technical contribution of the GPT-4 project was the discovery that the behavior of massive systems can be accurately predicted using tiny prototypes. By training models with as little as 1/10,000th of the final compute, the researchers used power law fits to forecast GPT-4’s final performance on tasks like coding and basic reasoning. This revealed that the most complex behaviors of large-scale models are not mysterious emergences but predictable outcomes of increased data and computation. It proved that the path to artificial general intelligence may be less about trial and error and more about the rigorous application of scaling laws that define how information is processed as a system grows. It suggested that we can now build the blue-prints for intelligence with the same confidence that engineers use to design bridges or airplanes.
Multimodal Capabilities

GPT-4 solving a physics problem involving a diagram written in French.
GPT-4 introduced a significant architectural shift by being natively designed to accept both text and image inputs. Instead of using a separate 'vision' brain and a 'language' brain that are crudely connected, GPT-4 processes visual data in the same way it processes words—by breaking an image into tokens that the central model can reason about. This allows the model to solve complex problems that require a simultaneous understanding of visual and textual information, such as explaining a physics problem from a diagram or interpreting the nuances of a comic strip. This finding suggested that the boundaries between different forms of data are largely artificial. It revealed that a sufficiently powerful model can learn a generalized representation of the world that transcends any single sensory modality, moving closer to the way humans perceive their environment.
Alignment and Rule-Based Reward Models
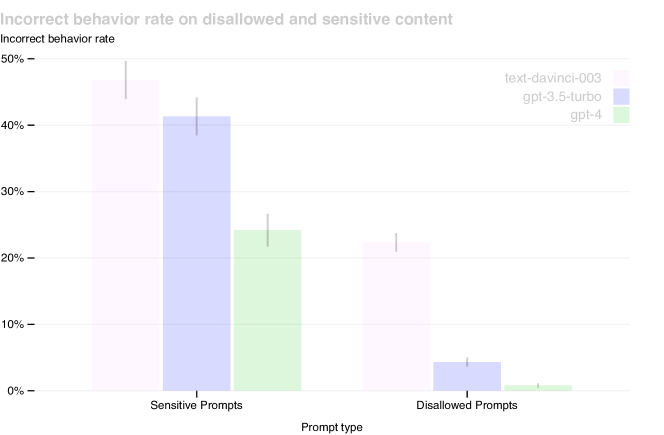
Reduction in incorrect behavior on sensitive prompts through RLHF and safety alignment.
How GPT-4 achieves a high level of professional performance is tied to its post-training alignment process, which uses other models to act as 'safety instructors.' The researchers utilized Rule-Based Reward Models, which are automated classifiers that provide a consistent signal to the model, ensuring it refuses harmful requests in a helpful tone. This approach led to an 82% reduction in the tendency to respond to disallowed content compared to GPT-3.5. It proved that the safety and reliability of a model are not just side effects of its training but are specific, engineerable traits that can be systematically improved. It raised the question of whether the future of AI safety lies in increasingly complex human oversight or in the creation of automated systems that can enforce ethical constraints at the speed of thought.
The Professional Threshold
The most visible impact of GPT-4 was its performance on professional and academic examinations designed for humans. On the Uniform Bar Exam, GPT-4 scored in the 90th percentile, a massive leap from GPT-3.5’s performance in the bottom 10%. This success revealed that the 'reasoning' capabilities of large models have reached a threshold where they can effectively handle tasks that were previously thought to require deep, specialized human expertise. It suggested that many professional tasks are not as uniquely human as once believed, and that the continued scaling of these models will inevitably challenge our definitions of expertise and cognitive labor. It remains to be seen how society will adapt to a world where professional-grade reasoning is available as a scalable utility.
Dive Deeper
GPT-4 Technical Report (arXiv)
arXiv • article
Explore ResourceOpenAI GPT-4 Blog
OpenAI • article
Explore Resource