Join the Menttor community
Access accelerated AI inference, track progress, and collaborate on roadmaps with students worldwide.
Self-Refine: Iterative Refinement
Madaan, A., Tandon, N., Gupta, P., Hallinan, S., Gao, L., Wiegreffe, S., ... & Clark, P. (2023). Self-refine: Iterative refinement with self-feedback. arXiv preprint arXiv:2303.17651.
Read Original Paper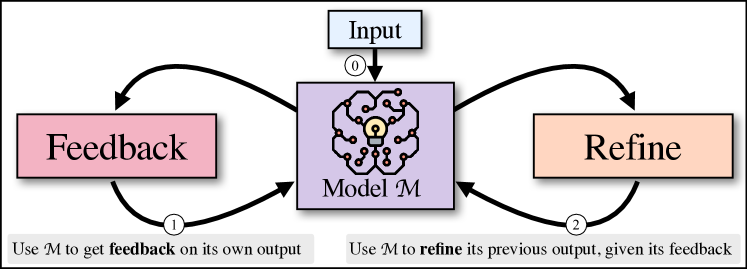
The 2023 'Self-Refine' paper introduced a method where a single large language model improves its own outputs through an iterative loop of feedback and correction. While traditional performance tuning requires external fine-tuning or human intervention, researchers at Carnegie Mellon and the Allen Institute showed that a model can leverage its own evaluative knowledge to critique and fix its own mistakes. It was a shift from viewing the model's first generation as a final product to viewing it as an initial draft in a recursive, self-correcting process.
The Generate-Feedback-Refine Loop
The iterative Self-Refine loop: generating, critiquing, and refining without human assistance.
The technical shift in Self-Refine was the implementation of a three-step iterative cycle: Initial Generation, Feedback, and Refinement. In this process, the model first produces a draft response. It then generates a natural language critique of its own output, focusing on specific qualitative dimensions such as code efficiency, dialogue relevance, or mathematical logic. Finally, the model uses this feedback to produce a refined version. This cycle repeats up to four times, allowing the model to 'polish' its work without any additional training or human feedback. It proved that the 'raw' output of a model is often a poor reflection of its true underlying knowledge, which can be unlocked through iterative reflection.
Actionable and Specific Critique
The key to successful self-refinement lies in the quality of the feedback, which the researchers mandated must be both 'actionable' and 'specific.' Instead of broad judgments like 'make it better,' the model is prompted to identify concrete logical errors or inefficient patterns, such as a redundant loop in code or a missing constraint in a word puzzle. By retaining the history of previous drafts and critiques, the model avoids repeating its mistakes and progressively converges on a higher-quality result. This finding revealed that a model's 'evaluator' capability is often significantly more advanced than its 'generator' capability. It suggested that intelligence is not just the ability to produce information, but the ability to recognize and correct deviations from a goal.
Transcending One-Pass Generation
The iterative approach achieved absolute performance gains of approximately 20% across diverse tasks, including code optimization and dialogue generation. In dialogue tasks specifically, GPT-4's preference scores tripled after just a few rounds of self-refinement. These results proved that multi-step reasoning can bridge the gap between weak and strong model performance, allowing even mid-sized models to handle complex constraints that they would otherwise fail in a single pass. However, it also revealed a diminishing return after the first two iterations, suggesting that there is a finite limit to how much a system can improve without external grounding or new data. It raises the question of whether the future of AI lies in larger weights or in more sophisticated architectures for internal reflection.
The Echo Chamber Effect
Despite its power, Self-Refine highlights the 'echo chamber' effect where a model may become blind to its own biases if they are shared by both its generator and evaluator components. There is a fundamental limit to how much a closed system can improve without access to an external source of truth. This reveals a critical challenge in autonomous AI: the need for models that can identify when their internal evaluation is no longer sufficient and when they must seek information from the outside world. It remains to be seen if iterative refinement can be combined with real-world feedback to create agents that are truly capable of self-directed learning and evolution.
Dive Deeper
Self-Refine Project Site
Self-Refine Team • docs
Explore ResourceSelf-Refine Paper on arXiv
arXiv • article
Explore Resource