Join the Menttor community
Access accelerated AI inference, track progress, and collaborate on roadmaps with students worldwide.
Mistral 7B: Efficient LLM
Jiang, A. Q., Sablayrolles, A., Mensch, A., Bamford, C., et al. (2023). Mistral 7B. arXiv:2310.06825.
Read Original Paper
The 2023 paper on 'Mistral 7B' challenged the prevailing 'scaling laws' that had dominated the artificial intelligence landscape for years. Before Mistral, the industry largely assumed that model capability was a direct function of parameter count—if you wanted more reasoning power, you simply built a larger model with a more massive dataset. Researchers at Mistral AI proposed a shift: instead of chasing scale, they focused on architectural efficiency. By using techniques like Sliding Window Attention and Grouped-Query Attention, they created a 7-billion parameter model that consistently outperformed models twice its size. It was a transition from 'brute-force' scaling to a more nuanced, 'inference-first' engineering approach, proving that how a model thinks is just as important as how much it knows.
The Sliding Window Shift
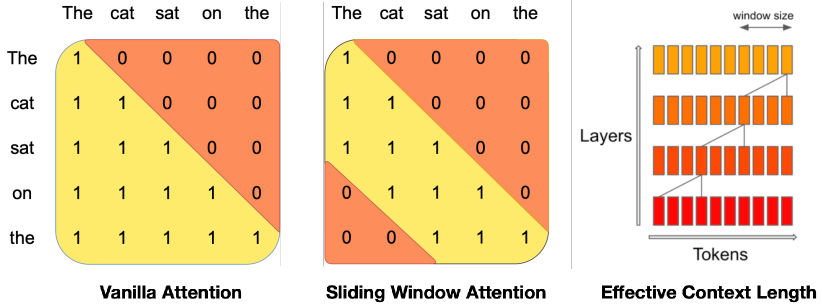
Sliding Window Attention allowing information to propagate across the entire sequence through stacked layers.
The fundamental technical contribution of Mistral 7B was the implementation of Sliding Window Attention. Instead of a model trying to remember every word in a long conversation at once, Mistral only focuses on a fixed window of the most recent 4,096 tokens. However, because these layers are stacked, the information from earlier in the conversation 'cascades' upward through the layers. This revealed that a model does not need to look at every token simultaneously to maintain a coherent global context. It proved that the 'effective' memory of a model can be much larger than its immediate window, allowing for a 131,000-token context span with a fraction of the memory. This finding suggested that the bottleneck in AI was not the size of the memory, but the efficiency with which information is passed between tokens as the model processes them.
Rolling Buffer Memory

The Rolling Buffer Cache overwriting past values to maintain a fixed memory footprint during inference.
How Mistral manages long sequences during inference lies in its use of a Rolling Buffer Cache, which treats memory like a rotating conveyor belt. Traditional models have a memory requirement that grows with every new word, eventually hitting hardware limits. Mistral's cache remains at a fixed size, overwriting the oldest data as new words are generated. This revealed that the 'state' of a conversation can be mathematically treated as a rolling signal rather than a constantly expanding history. By using heads that are grouped together to limit memory usage, the model achieved an 8x reduction in cache usage without a loss in coherence. It proved that the true efficiency limit of small models is far higher than previously assumed, making powerful AI accessible on consumer-grade hardware by rethinking how the machine stores what it has just said.
The Efficiency Frontier
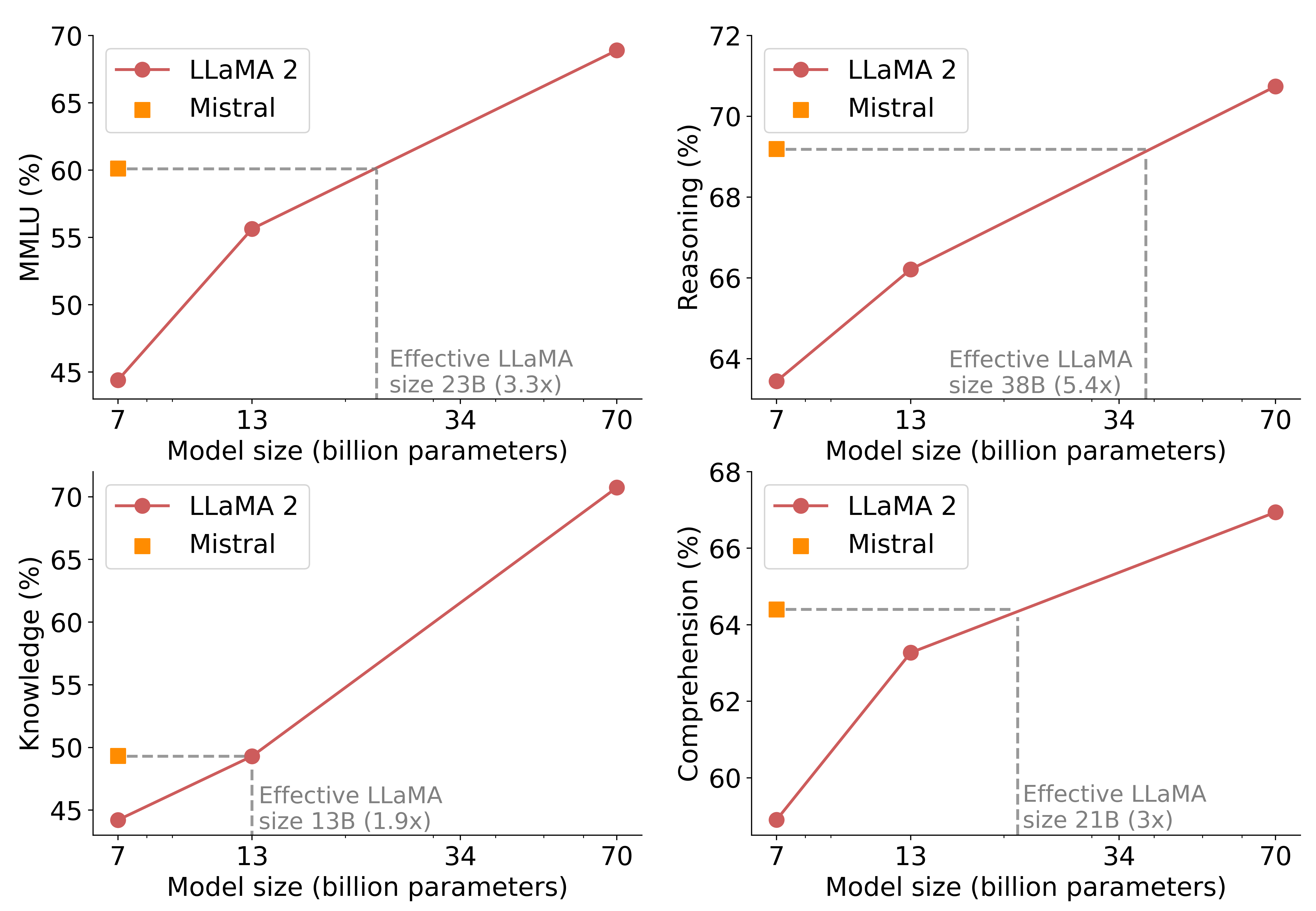
Mistral 7B performance on MMLU compared to larger Llama models.
The success of Mistral 7B was most evident in its performance across mathematics, coding, and reasoning benchmarks, where it surpassed models like Llama 2 13B. This finding revealed that intelligence is not a monolithic property of scale but an emergent result of high-signal training and efficient architecture. It proved that a smaller model can compress the same amount of 'knowledge' as a much larger one if the underlying data representation is sufficiently dense and the inference mechanism is properly optimized. This raises the question of whether the future of AI lies in increasingly massive systems or in the continued refinement of smaller, more specialized 'foundation' models that can be run on local hardware. It suggested that the next leap in capability will come from models that are built to be efficient from the first line of code.
Dive Deeper
Mistral 7B Blog Post
Mistral AI • article
Explore ResourceMistral 7B Paper on arXiv
arXiv • article
Explore ResourceGitHub Implementation
GitHub • code
Explore Resource