Join the Menttor community
Access accelerated AI inference, track progress, and collaborate on roadmaps with students worldwide.
DALL-E 2: Hierarchical Generation
Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., & Chen, M. (2022). Hierarchical text-conditional image generation with CLIP latents. arXiv preprint arXiv:2204.06125.
Read Original Paper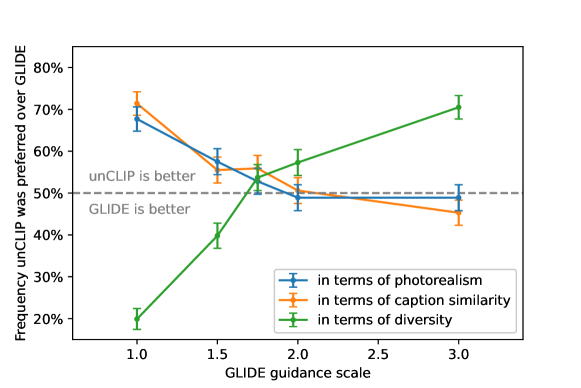
In 2022, OpenAI’s 'DALL-E 2' (or 'unCLIP') introduced a two-stage approach to generating high-fidelity images from natural language descriptions. While previous models like the original DALL-E directly mapped text tokens to image pixels, researchers proposed a hierarchical system that first maps text to a CLIP image embedding and then decodes that embedding into a final image. It was a shift from viewing image generation as a single translation task to viewing it as a multi-step reconstruction of visual concepts.
The unCLIP Architecture
The DALL-E 2 (unCLIP) architecture: mapping text to image embeddings via a prior, then decoding.
The technical shift in DALL-E 2 was the introduction of 'unCLIP,' a two-stage process that first predicts a CLIP image embedding from a text prompt and then decodes that embedding into pixels. This approach moved away from the direct text-to-pixel mapping used in the original DALL-E. By breaking the generation into two parts—intent (the embedding) and execution (the pixels)—the researchers gained a way to control image variations and style without altering the core semantic meaning. It proved that image generation is more efficient when it is guided by a high-level conceptual map rather than a sequence of raw tokens.
The Diffusion Prior
The first stage of unCLIP, the 'prior,' is a Transformer-based model that generates a continuous CLIP image embedding. The researchers compared two approaches: an autoregressive prior, which required reducing the embedding's dimensionality, and a diffusion prior, which operated on the full vector space. The diffusion prior was found to be computationally more efficient and produced higher-quality results, as it could better handle the continuous nature of visual representations. This finding suggested that diffusion processes are inherently better suited for mapping between different semantic spaces than discrete, token-based prediction. It revealed that the 'prior' is the engine of creativity in the system, while the decoder is simply the executor of visual detail.
Decoding via GLIDE
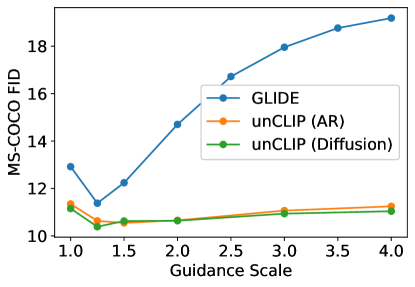
The second stage is a 3.5 billion parameter diffusion model based on the GLIDE architecture, which 'inverts' the predicted CLIP embedding to create the final image. This decoder is conditioned on the CLIP vector through two mechanisms: it is added to the timestep embedding and projected into extra context tokens. To reach a final resolution of 1024x1024, the system employs a hierarchical chain of diffusion upsamplers. By using classifier-free guidance, the model can be pushed toward high photorealism without losing the semantic diversity captured in the latent space. This hierarchical decoding proved that the most effective way to generate high-resolution data is to first master the low-frequency conceptual structure before filling in the high-frequency visual details.
Traversing the Latent Space
The reasoning behind this hierarchical approach was to leverage the power of CLIP’s joint text-image space for practical editing and variation. Because the model represents an image as a bipartite latent—consisting of a CLIP embedding and a diffusion latent—it can generate 'semantic variations' of an input image by keeping the embedding fixed while varying the noise. This allows for precise control over an image's composition while maintaining its core identity. It revealed that the future of generative AI lies in the ability to traverse these high-level latent spaces, enabling users to blend concepts or explore different visual interpretations of the same underlying idea.
The Compositional Frontier
While DALL-E 2 produced stunning results, its reliance on CLIP embeddings also highlighted a 'compositional bottleneck' where the model sometimes fails to bind specific attributes to the correct objects in a scene. Because CLIP compresses a complex image into a single vector, it can lose the precise spatial relationships and attribute assignments defined in the text. This reveals a fundamental challenge: high-level semantic representation is efficient for general concepts but can be too 'lossy' for complex, multi-object reasoning. It raises the question of whether true compositional understanding requires a different architectural bias that preserves spatial geometry more explicitly during the encoding process.
Dive Deeper
OpenAI DALL-E 2 Blog
OpenAI • article
Explore ResourceDALL-E 2 Explanation
Towards Data Science • article
Explore ResourceDALL-E 2 Paper on arXiv
arXiv • article
Explore Resource