Join the Menttor community
Access accelerated AI inference, track progress, and collaborate on roadmaps with students worldwide.
BERT: Bidirectional Transformers
Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
Read Original Paper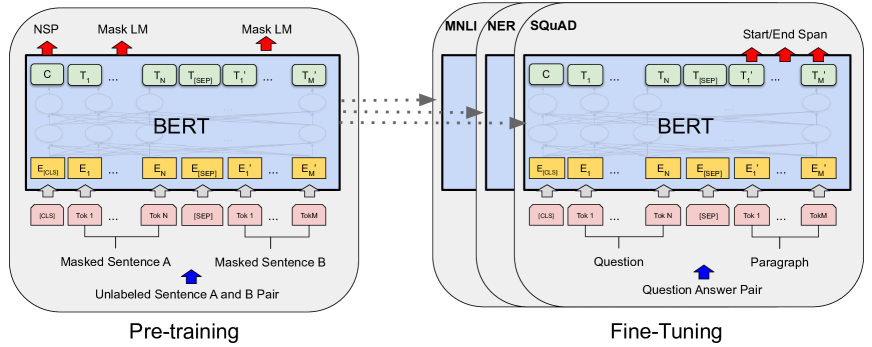
The realization that language understanding requires context from both directions led to the development of BERT in 2018. Before this, models processed text primarily from left to right, which is effective for prediction but limits the model's ability to grasp the full relationship between words. If a word’s meaning depends on what comes after it, a unidirectional model will inevitably miss the nuance. The researchers at Google proposed a bidirectional approach that changed how representations are built.
Bidirectional Context
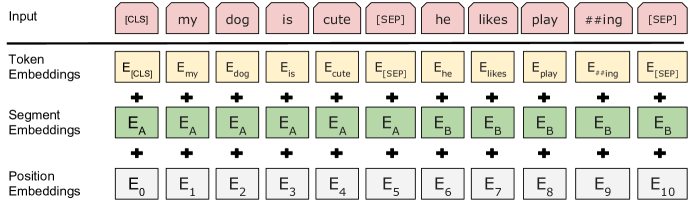
BERT input representation utilizing token, segment, and position embeddings.
The technical shift was the Masked Language Model (MLM) objective. By masking 15% of the tokens in a sequence and requiring the model to predict them using all other tokens, BERT forced the transformer to attend to context from both the left and the right simultaneously. It is a method that moves beyond the sequential nature of reading. The model is not just predicting the next word; it is reconstructing a missing piece of a complete thought.
Sentence Relationships
A second objective, Next Sentence Prediction (NSP), was introduced to capture relationships between larger blocks of text. The model was trained to identify whether one sentence naturally follows another. This pushed the model to understand coherence and logical flow rather than just local word associations. It suggests that language is not just a collection of words, but a structured hierarchy of ideas that must be linked together.
The Transfer Learning Shift
The success of BERT proved that a single, large pre-trained model could be adapted to nearly any NLP task with minimal modification. Instead of building specific architectures for translation, sentiment analysis, or question answering, developers could simply fine-tune the same base model. This consolidated the field around a few powerful architectures, raising questions about whether the future of AI lies in scale rather than specialized design.
Dive Deeper
Open Sourcing BERT
Google AI • article
Explore ResourceBERT Explained
Towards Data Science • article
Explore Resource