Join the Menttor community
Access accelerated AI inference, track progress, and collaborate on roadmaps with students worldwide.
Word2Vec: Distributed Representations
Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., & Dean, J. (2013). Distributed representations of words and phrases and their compositionality. Advances in neural information processing systems, 26.
Read Original Paper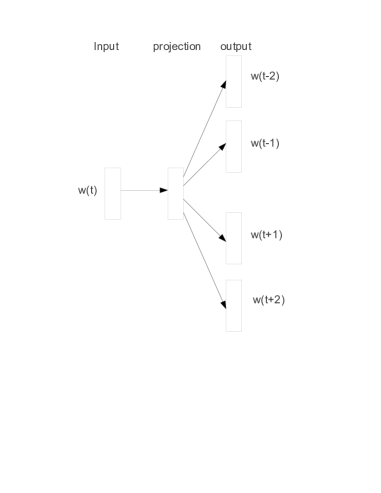
The 2013 Word2Vec paper by Tomas Mikolov and his team at Google fundamentally altered how machines perceive human language by mapping words into a continuous geometric space. Before this breakthrough, words were treated as atomic, discrete symbols—meaningless indices in a vast dictionary that lacked any mathematical relationship to one another. The paper argued that the meaning of a word is not an isolated definition but is instead defined by its context, suggesting that words appearing in similar environments should be positioned close together in a high-dimensional vector space. This shift from discrete labels to dense vectors allowed computers to perform 'semantic arithmetic,' where the relationship between concepts could be calculated with the precision of coordinate geometry.
Semantic Geometry

Linear vector relationships showing semantic analogies like King-Man+Woman=Queen.
The core technical shift was the use of distributed representations, where the 'meaning' of a word is spread across hundreds of dimensions rather than being confined to a single bit. By training a shallow neural network to predict a center word from its neighbors—the Skip-gram architecture—the researchers forced the model to learn a representation that captures subtle semantic nuances. In this space, the vector for 'dog' is naturally pulled toward 'cat' and 'pet' because they share similar linguistic contexts, while being pushed away from unrelated concepts like 'uranium' or 'syntax.' This revealed that human language possesses an underlying topological structure that can be reconstructed through simple predictive tasks. It proved that the most effective way to represent a concept is not to describe it directly, but to observe its influence on its surroundings.
Relational Structure
A profound finding was the emergence of linear relationality, where semantic relationships are captured as consistent vector offsets. The discovery that vec('King') - vec('Man') + vec('Woman') results in a vector closest to 'Queen' showed that the model had autonomously learned the concept of gender as a specific direction in space. This relational structure extended to geography, verb tenses, and even idiomatic phrases. The researchers introduced a data-driven approach to identify phrases like 'Air Canada' or 'Boston Globe' as single tokens, preventing the model from diluting their specific meanings into their constituent words. This suggested that meaning is not just compositional but can be found in the unique intersections of words that behave as distinct entities. It revealed that a sufficiently large map of word usages eventually begins to mirror the logical structure of human thought.
Feasibility at Scale
The ability to train these models on 100 billion words in a single day was made possible by two critical optimizations: negative sampling and subsampling of frequent words. Standard neural language models were computationally bottlenecked by the need to update the weights for every word in the vocabulary for every training example. Negative sampling replaced this expensive process by only updating the weights for the target word and a few randomly selected 'negative' examples, dramatically reducing the work required per step. Simultaneously, subsampling common words like 'the' or 'in' allowed the model to spend more time learning the rare, high-information words that define a sentence's meaning. These engineering choices proved that the progress of AI is often driven as much by the removal of computational waste as it is by the addition of complexity. It set the stage for a new era of 'data-centric' machine learning where scale became the primary engine of capability.
Maps and Territories
Despite the elegance of semantic geometry, there is a lingering risk of mistaking the mathematical map for the linguistic territory. The ability to calculate the distance between vectors does not necessarily imply a genuine understanding of intent or the dynamic nature of communication. A static vector space captures the average usage of a word over a massive corpus, but it struggles to adapt to the shifting meanings of words in real-time or the unique contexts of specific conversations. This raises a fundamental question about whether a fixed coordinate system can ever truly capture the fluid, evolving nature of human expression. It remains to be seen if the next leap in language understanding will require moving beyond static maps into representations that can reshape themselves in response to the intent of the speaker.
Dive Deeper
The Illustrated Word2Vec
Jay Alammar • article
Explore ResourceGoogle Word2Vec Archive
Google • docs
Explore Resource