Join the Menttor community
Access accelerated AI inference, track progress, and collaborate on roadmaps with students worldwide.
YOLO: You Only Look Once
Redmon, J., Divvala, S., Girshick, R., & Farhadi, A. (2016). You only look once: Unified, real-time object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 779-788).
Read Original Paper
In 2015, the YOLO (You Only Look Once) paper by Joseph Redmon and his colleagues proposed a unified approach to object detection that prioritized real-time speed without a catastrophic loss in accuracy. Before this, detection systems were complex, multi-stage pipelines that first proposed potential object regions and then classified those regions in a second pass. This was inherently slow and difficult to optimize because each stage had to be trained separately. Redmon argued that detection should instead be treated as a single regression problem, directly mapping raw image pixels to bounding box coordinates and class probabilities. This shift toward architectural simplicity suggested that the most effective way to understand a scene is to look at it as a single, coherent entity.
Unified Detection
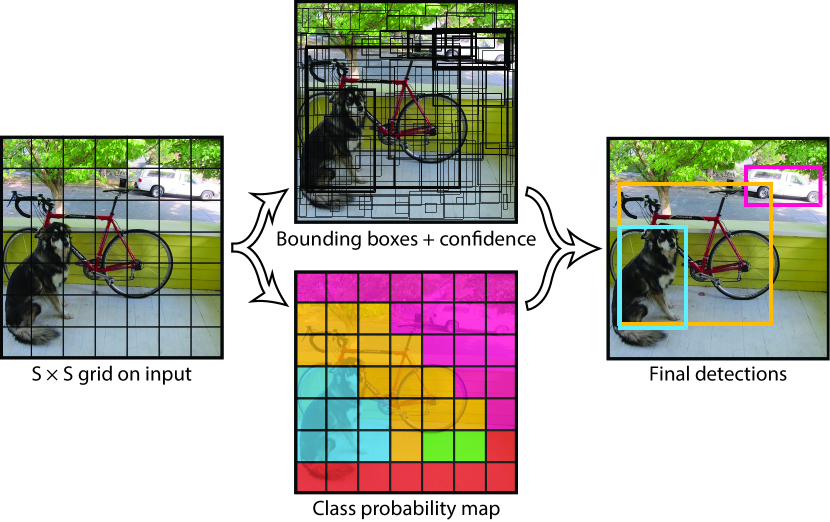
The YOLO model divides an image into a grid and predicts bounding boxes and probabilities simultaneously.
The primary technical shift was the division of the image into a fixed S x S grid. For each grid cell, the network predicts multiple bounding boxes and confidence scores, along with a probability distribution over different object classes. Because the entire detection process happens in a single forward pass through a convolutional neural network, the model can reason globally about the image and its context. Unlike sliding-window or region-proposal methods, which only see small patches of the image, YOLO 'sees' the background and the objects simultaneously, allowing it to avoid common mistakes like confusing patches of sky with airplanes. It revealed that the accuracy of a detection is not just a function of local detail, but of how that detail fits into the broader visual environment.
Real-Time Inference
The reasoning behind this unified design was the critical need for real-time performance in applications like robotics and autonomous driving. By framing detection as a single pass, the researchers demonstrated that their model could process images at 45 frames per second on a standard GPU, and over 150 frames per second in a smaller 'Fast YOLO' version. This proved that in many practical scenarios, the value of an AI model is not just its peak accuracy on a static dataset, but its ability to respond to a rapidly changing environment in real-time. It suggested that efficiency is not just an optimization but a core component of a system's functional utility, enabling machines to act with the same speed as biological organisms.
The Localization Trade-off
The move to a global, unified model introduced a significant trade-off in the form of localization errors. While YOLO was excellent at avoiding background mistakes, it struggled with the precise placement of bounding boxes around small objects or dense groups, such as a flock of birds. This highlighted a fundamental tension in computer vision between the ability to reason about the global context of a scene and the ability to capture its minute, local details. This finding proved that no single architectural choice is a universal solution; every optimization for speed or global understanding comes with a corresponding loss in fine-grained precision. It raises the question of whether future systems will require a hybrid approach that can dynamically shift its attention between the broad overview and the specific detail.
Dive Deeper
YOLO Official Site
PJ Reddie • docs
Explore ResourceReal-time Object Detection
Towards Data Science • article
Explore Resource