Join the Menttor community
Access accelerated AI inference, track progress, and collaborate on roadmaps with students worldwide.
ViT: The Vision Transformer
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., ... & Houlsby, N. (2020). An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929.
Read Original Paper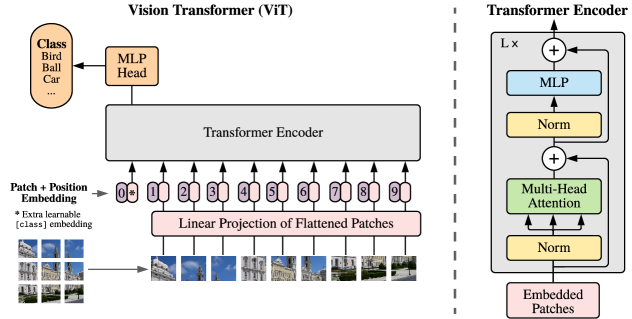
The 2020 paper 'An Image is Worth 16x16 Words' challenged the long-held assumption that convolutional neural networks (CNNs) were the only viable architecture for computer vision. For over a decade, the field of vision had relied on hand-coded inductive biases—such as translation invariance and locality—to process pixel data. Researchers at Google suggested that these biases, while helpful on small datasets, eventually become a limitation as the amount of data increases. They proposed that the Transformer architecture—which had already revolutionized natural language processing—could be applied directly to images by simply treating them as sequences of 'visual words.' It was an argument for the universality of the Transformer, suggesting that any data type can be processed through a single, general-purpose mechanism if it is structured correctly.
Patches as Tokens
ViT architecture: an image is split into patches, embedded, and processed as a sequence by a Transformer.
The technical shift in the Vision Transformer (ViT) was the decision to treat an image as a sequence of discrete patches rather than a continuous grid of pixels. The model divides an image into fixed-size squares (e.g., 16x16 pixels), flattens them into vectors, and embeds them into a high-dimensional space just as one would embed words in a sentence. Because the Transformer lacks the built-in 'understanding' of spatial proximity that convolutions provide, it must learn the relationship between these patches from scratch through self-attention. This process revealed that the specific geometry of an image is not a necessary starting point for a machine, but rather a pattern that can be discovered through enough exposure. It proved that a model with fewer built-in assumptions can eventually outperform a more specialized one if it is given the freedom to discover its own rules.
The Scale Requirement
The reasoning behind the ViT was that the 'inductive biases' of CNNs act as a form of training wheels that become a drag at high speeds. The researchers found that while ViT performed poorly when trained on standard datasets like ImageNet (1.3M images), its performance scaled much more aggressively than CNNs when pre-trained on massive datasets like ImageNet-21k (14M images) or JFT-300M. This demonstrated a fundamental trade-off in AI architecture: specialized models are more efficient with limited data, but general models possess a higher ceiling when data is abundant. This finding marked a shift in the industry toward 'scaling laws,' where the success of a system is increasingly determined by the volume of information it has ingested rather than the cleverness of its manual design.
Global Attention in the First Layer
A profound difference between ViT and traditional vision models is the use of global self-attention across the entire image from the very first layer. In a CNN, a neuron only 'sees' a small local neighborhood, and global understanding only emerges in the deeper layers as these local features are pooled together. In ViT, every patch can interact with every other patch immediately, allowing the model to capture long-range dependencies and global structure—such as the relationship between a person's hand and their face—without waiting for multiple layers of processing. This revealed that the most effective way to understand a complex scene is not to build it up from tiny pieces, but to observe all the pieces simultaneously in a single, parallelized operation. It raises the question of whether our human-centric focus on local 'features' has been a distraction from the true power of global, relational thinking.
Dive Deeper
Google AI Blog: ViT
Google AI • article
Explore ResourceViT Implementation
GitHub • code
Explore Resource