Join the Menttor community
Access accelerated AI inference, track progress, and collaborate on roadmaps with students worldwide.
Phi-2: Textbook-Quality
Li, Y., Bubeck, S., Eldan, R., Del Giorno, A., Gunasekar, S., & Lee, Y. T. (2023). Textbooks Are All You Need II: phi-1.5 Technical Report. arXiv:2309.05463.
Read Original Paper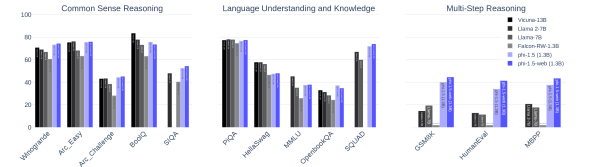
The 2023 paper on 'Phi-2' fundamentally challenged the 'Chinchilla scaling laws' that had become the industry standard for AI development. Before Phi, the prevailing wisdom was that a model's intelligence was a proportional result of its size and the sheer volume of its training data. Researchers at Microsoft Research proposed a shift: instead of training on trillions of noisy web-crawled tokens, they focused on 'textbook-quality' data. By curating a high-signal mixture of synthetic stories and filtered educational content, they created a 2.7-billion parameter model that could match or exceed the reasoning capabilities of models 25 times its size. It was a transition from 'data quantity' to 'data quality,' proving that intelligence is not just a function of scale but of the signal-to-noise ratio in the training process.
The Textbook-Quality Shift
Phi-1.5 performing comparably to models 10x larger in reasoning tasks.
The core technical shift in the Phi project was the move away from raw web data toward 'textbook-quality' sources. Instead of scraping the entire internet, which contains a massive amount of repetitive and low-quality text, the researchers used NLP techniques to filter 1.2 trillion tokens down to a high-signal set of educational content. This approach revealed that a model's 'reasoning' is a skill that can be taught through structured, logical examples rather than just through exposure to the sheer volume of human language. It proved that a relatively small number of parameters are sufficient to hold a high level of logical fluency if the training data is carefully curated. This finding suggested that the 'bottleneck' in AI was not the number of parameters, but the inclusion of distracting data that forces the model to learn noise instead of logic.
Synthetic Reasoning Data

Safety and toxicity scores for Phi-1.5 compared to other open-source LLMs.
How the researchers achieved such high common-sense performance in a small model lies in their use of a synthetic dataset designed to teach specific concepts. They used existing large models to generate thousands of short stories and exercises that demonstrate daily activities, science, and social logic. This approach proved that synthetic data can be used to 'target' specific cognitive gaps in a model more effectively than raw human-generated text. It revealed that a model can act as its own teacher, creating examples that are more 'digestible' for a smaller architecture. By focusing on structured knowledge, the model developed a 'safety-by-default' profile, simply because it had never been exposed to the toxic tropes and biases that are commonly found on the open internet.
Challenging the Scaling Laws
The success of Phi-2 demonstrated that a 2.7B parameter model could outperform models like Llama 2 70B on specific reasoning and coding tasks. This finding revealed that the scaling laws which dictate how models should grow may be 'data-limited' rather than 'compute-limited.' It proved that the 'efficiency frontier' of small models is much further than previously thought, allowing for high-level logic to be run on mobile and edge devices. This raises the question of whether the next leap in AI will come from larger models or from a deeper understanding of how to curate the 'perfect' dataset for smaller ones. It suggested that in the future, 'what' a model learns may be more important than 'how much' it sees, moving the field toward a more surgical and deliberate approach to intelligence.
Dive Deeper
Phi-2 Blog Post
Microsoft Research • article
Explore ResourcePhi-1.5 Technical Report
arXiv • article
Explore ResourcePhi-2 Model on Hugging Face
Hugging Face • model
Explore Resource