Join the Menttor community
Access accelerated AI inference, track progress, and collaborate on roadmaps with students worldwide.
InstructGPT: Model Alignment
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., ... & Lowe, R. (2022). Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35, 27730-27744.
Read Original Paper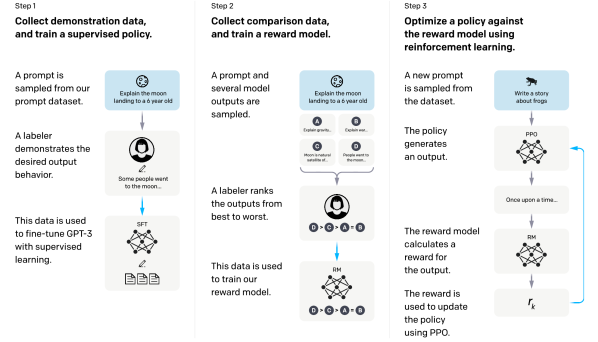
The problem with large language models is that they are trained to predict the next word on the internet, which is not necessarily the same as being helpful or following instructions. This 'misalignment' led to the development of InstructGPT in 2022. The researchers at OpenAI introduced a method to steer model behavior using human feedback, ensuring that the model’s outputs aligned more closely with what a user actually intended. It moved the focus from raw capability to the quality of the interaction.
Human-in-the-Loop Alignment
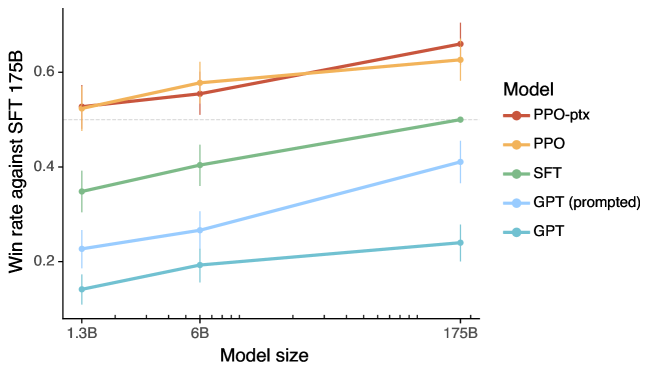
Human preference evaluations of InstructGPT vs standard GPT-3.
The technical shift was a three-step process called Reinforcement Learning from Human Feedback (RLHF). First, the model is fine-tuned on a small set of human-written demonstrations. Then, humans rank different model outputs to train a 'reward model.' Finally, the original model is optimized to maximize the score from this reward model. This process uses human judgment as a direct optimization signal, allowing the model to learn preferences that are difficult to define mathematically.
Following Intent
The result of this alignment is a model that is significantly better at following complex instructions, even at much smaller scales. The researchers found that outputs from a 1.3-billion parameter InstructGPT model were often preferred over the standard 175-billion parameter GPT-3. This demonstrates that raw size is less important than how the model is directed. It suggests that the 'knowledge' is already present in the pre-trained weights; the alignment process simply unlocks the ability to use it correctly.
The Safety Trade-off
Alignment also introduces new challenges, such as the risk of 'over-optimization' where the model becomes too helpful or loses some of its creative edge. There is a tension between making a model safe and keeping it useful for diverse tasks. This process reveals that the values of the people doing the ranking are ultimately encoded into the model’s behavior. It raises the question of whose intent a model should follow and how those values should be chosen for a global user base.
Dive Deeper
Aligning Language Models
OpenAI • article
Explore ResourceRLHF Explained
Hugging Face • article
Explore Resource