Join the Menttor community
Access accelerated AI inference, track progress, and collaborate on roadmaps with students worldwide.
DQN: Playing Atari with Deep RL
Mnih, V., Kavukcuoglu, K., Silver, D., Graves, A., Antonoglou, I., Wierstra, D., & Riedmiller, M. (2013). Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602.
Read Original Paper
The 2013 Deep Q-Network (DQN) paper from DeepMind demonstrated that a single AI agent could learn to play a variety of Atari 2600 games directly from raw pixels. Before this, reinforcement learning often required manual feature engineering to represent the state of the environment. The researchers proposed a method that combined Q-learning with deep neural networks, allowing the agent to discover its own features. It was a proof of concept that high-dimensional sensory input could be mapped directly to successful actions.
Experience Replay
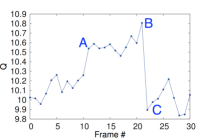
Visualization of the predicted value function for a segment of the game Seaquest.
A primary challenge in combining deep learning with reinforcement learning is that data is highly correlated and non-stationary. As the agent learns, the distribution of its experiences changes. To solve this, DQN introduced 'experience replay,' where the agent's experiences are stored in a buffer and sampled randomly to train the network. As the paper states, 'By using experience replay, the network can learn from a more diverse set of experiences and avoid getting stuck in local optima.' This stabilized the training process and allowed for more efficient use of data.
Deep Q-Learning
The technical shift was the use of a deep convolutional neural network to approximate the optimal action-value function. By feeding raw frames into the network and outputting a score for each possible action, the agent learned to associate visual patterns with long-term rewards. The 'aha!' moment was the discovery that the same architecture could achieve human-level performance across seven different games without any task-specific tuning. It suggested that general intelligence could emerge from a simple objective: maximize the expected future reward.
The Sensory Limit
Despite its success, DQN revealed limitations in how agents perceive time and context. Because the network only saw a few frames at a time, it struggled with games that required long-term planning or memory. This highlighted a fundamental question in AI: is intelligence primarily about reacting to the present moment, or about building an internal model of the world that persists over time? It remains to be seen if more complex architectures can eventually bridge the gap between reactive behavior and genuine reasoning.
Dive Deeper
DeepMind DQN Blog
DeepMind • article
Explore ResourceDQN Paper Explained
Towards Data Science • article
Explore Resource