Join the Menttor community
Access accelerated AI inference, track progress, and collaborate on roadmaps with students worldwide.
GPT-3: Few-Shot Learners
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., ... & Amodei, D. (2020). Language models are few-shot learners. Advances in neural information processing systems, 33, 1877-1901.
Read Original Paper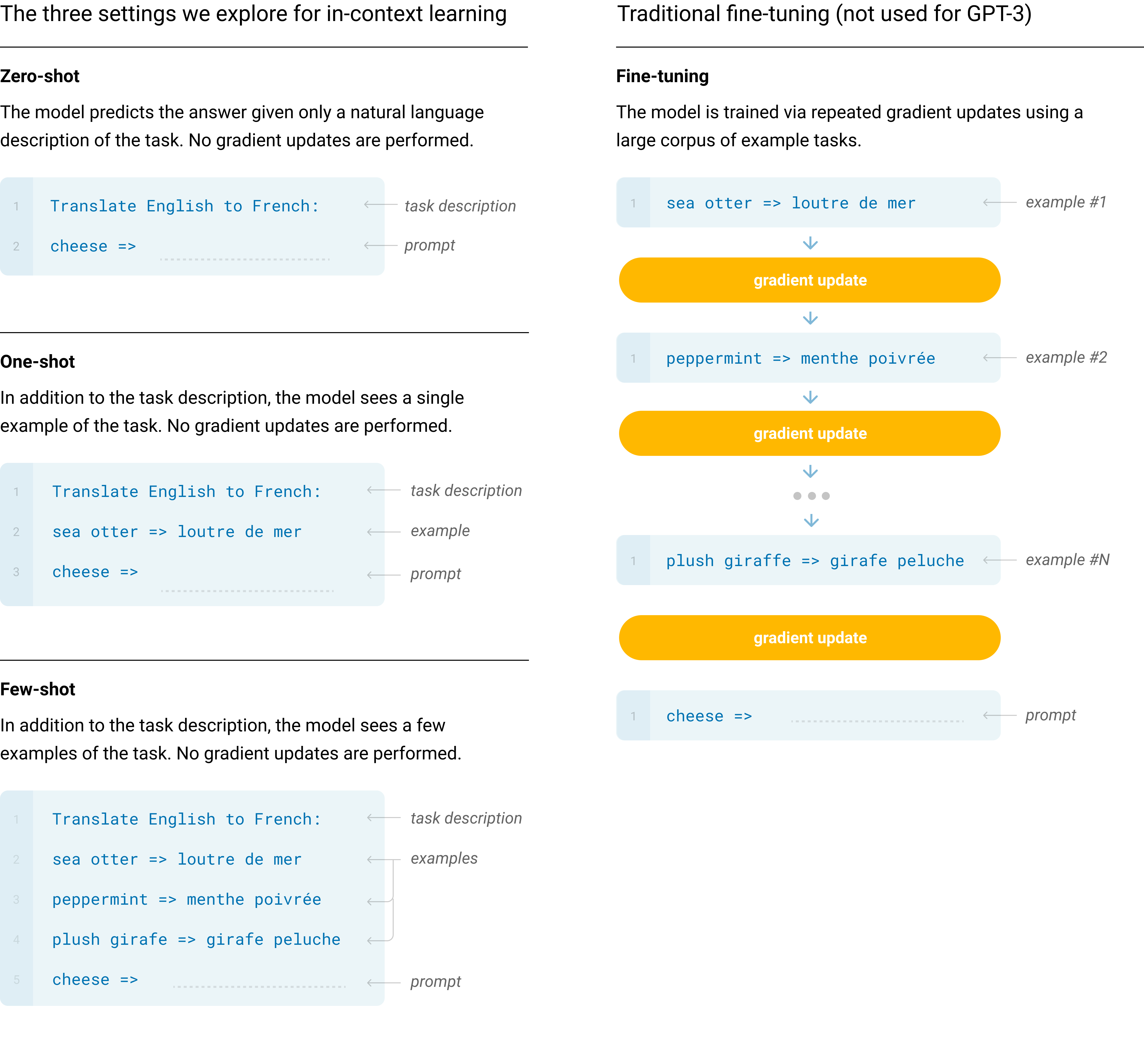
The 2020 paper on GPT-3 marked a departure from the fine-tuning paradigm that had dominated the previous few years. As models grew larger, the requirement to have thousands of labeled examples for every new task became an obvious bottleneck. OpenAI researchers argued that a model with 175 billion parameters would be large enough to learn tasks directly from its context. They demonstrated that scaling the model was not just about increasing accuracy, but about changing the nature of how a model interacts with information.
In-Context Learning
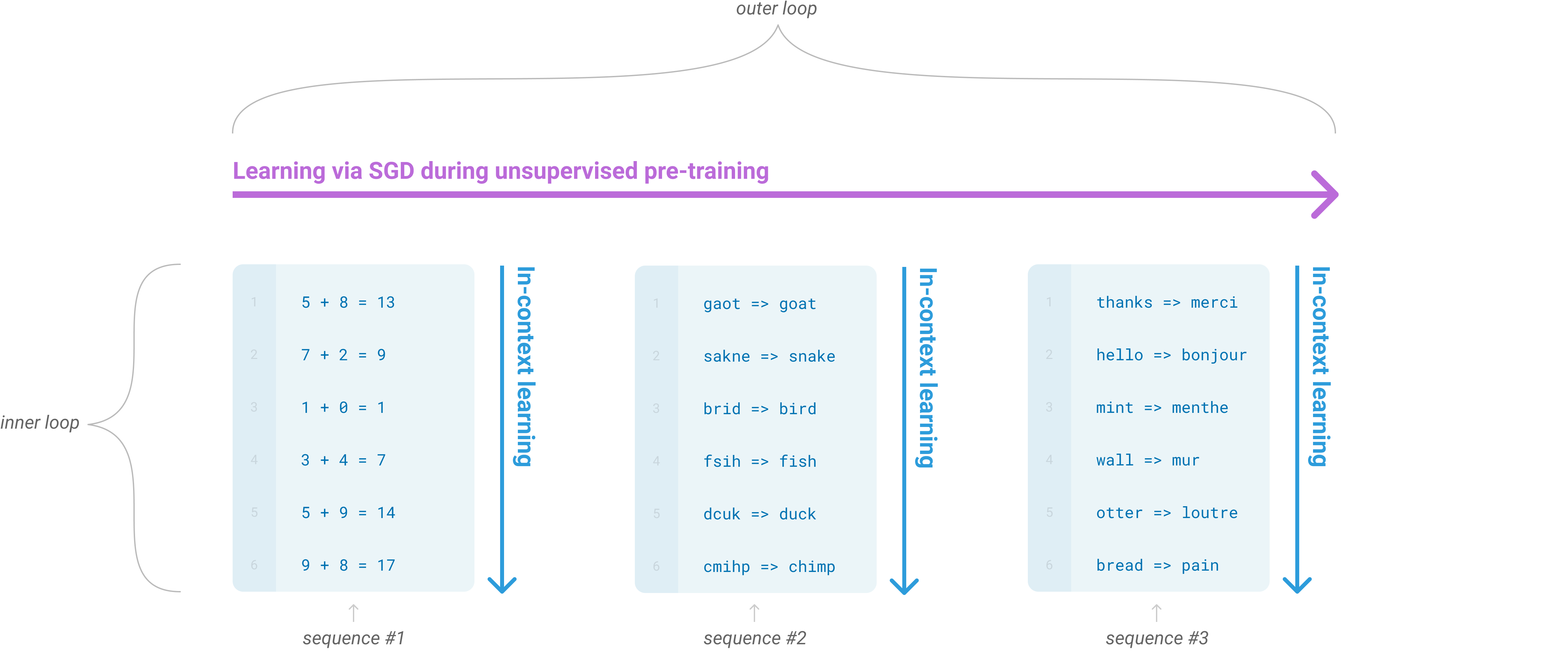
Language model meta-learning showing in-context learning loops.
The core idea is 'in-context learning,' where the model adapts to a task without any weight updates. By simply providing a few examples within the prompt, the model recognizes the pattern and continues it. This is referred to as 'few-shot' learning. It suggests that pre-training on a massive corpus of text allows a model to develop a broad set of skills that can be activated on demand. The model becomes a generalist that identifies the logic of a request in real-time.
Scaling as a Strategy
The shift to 175 billion parameters was a ten-fold increase over its predecessor, GPT-2. This scale allowed the model to handle tasks it was never explicitly trained for, such as writing code or solving arithmetic problems. The researchers found that while zero-shot performance improved steadily, few-shot performance increased much more rapidly with size. It reveals that larger models are better at using the information they are given at inference time.
The Generalization Limit
This reliance on scale raises a fundamental question about the nature of intelligence in machines. If a model can solve a problem simply by seeing three examples, is it reasoning or just performing advanced pattern matching? The boundary between the two becomes increasingly thin as the model’s capacity grows. It remains to be seen if scaling alone can eventually overcome the inherent limitations of predicting the next token in a sequence.
Dive Deeper
OpenAI GPT-3 Blog
OpenAI • article
Explore ResourceLambda GPT-3 Guide
Lambda • article
Explore Resource