Join the Menttor community
Access accelerated AI inference, track progress, and collaborate on roadmaps with students worldwide.
RLHF: Helpful & Harmless
Bai, Y., Jones, A., Ndousse, K., Askell, A., Commission, G., ... & Kaplan, J. (2022). Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862.
Read Original Paper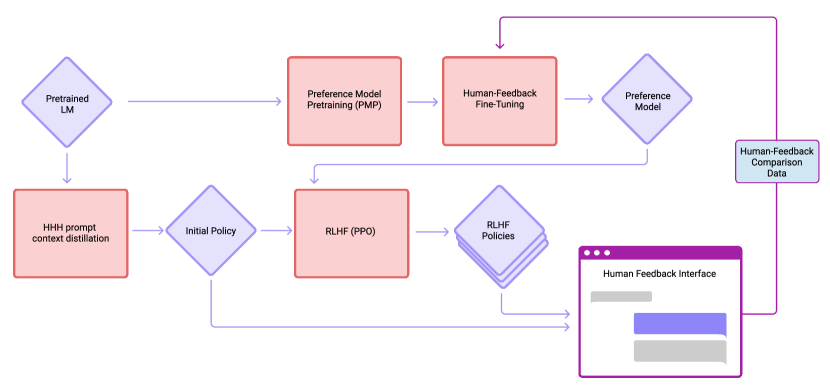
In 2022, the 'Helpful and Harmless' paper from Anthropic deepened the understanding of how Reinforcement Learning from Human Feedback (RLHF) can be used to align AI behavior. While previous work had focused on following simple instructions, this paper explored the inherent trade-offs between being useful to a user and avoiding harmful content. The researchers argued that alignment is not a single target, but a multi-dimensional space that requires careful data collection and model tuning. It was a push for safety as a core architectural requirement.
Preference Modeling
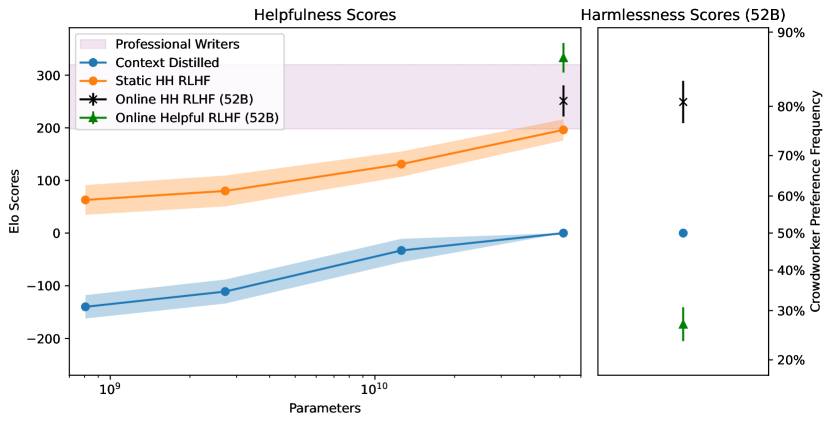
Crowdworker preferences across different model types and training methods.
The technical shift was the use of large-scale preference modeling to capture the nuances of what humans consider 'helpful' and 'harmless.' By showing crowdworkers multiple model responses and asking them to rank them, the researchers built a preference model that could then be used to train the main assistant. As the paper states, 'We find that RLHF leads to significant improvements in both helpfulness and harmlessness across all model sizes.' This revealed that the model's ability to be a good assistant is directly tied to the quality of the feedback it receives during training.
The Alignment Tax
The reasoning behind this work was the observation of an 'alignment tax'—the phenomenon where making a model safer or more helpful can sometimes lead to a decrease in its performance on other tasks. The researchers found that larger models were more robust to this tax, suggesting that scale provides the necessary capacity to handle conflicting objectives. This proved that building a safe AI is not just about constraints, but about having a model large enough to understand the complexity of human values.
Iterative Online Learning
The success of this approach highlighted the importance of iterative, 'online' learning, where the model is continuously updated based on new human interactions. This creates a feedback loop that allows the model to adapt to increasingly subtle and difficult scenarios. It raises the question of how we can scale this human-in-the-loop process to a global level, and whether the values of a small group of crowdworkers can ever truly represent the diverse needs of all users.
Dive Deeper
Anthropic RLHF Blog
Anthropic • article
Explore ResourceRLHF Concept Guide
Hugging Face • article
Explore Resource