Join the Menttor community
Access accelerated AI inference, track progress, and collaborate on roadmaps with students worldwide.
FlashAttention: IO-Awareness
Dao, T., Fu, D. Y., Ermon, S., Rudra, A., & Ré, C. (2022). FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. arXiv:2205.14135.
Read Original Paper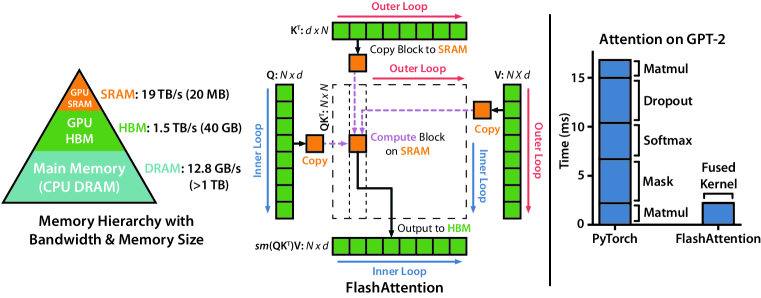
The 2022 paper on 'FlashAttention' introduced a fundamental optimization that allowed Transformers to break through the 'context wall' that had limited their memory for years. Before FlashAttention, the ability of a model to remember long sequences was constrained by a quadratic memory requirement—doubling the length of a conversation required four times the memory. Researchers at Stanford University proposed a shift: instead of trying to reduce the number of mathematical operations, they focused on the speed of data movement within the GPU. It was a transition from 'compute-bound' to 'memory-bound' thinking, proving that the bottleneck in modern AI is not how fast a chip can think, but how fast it can move its thoughts.
The Memory Wall
FlashAttention using tiling to prevent the materialization of the large attention matrix on slow GPU memory.
The core technical shift in FlashAttention was the realization that the primary delay in AI training is the constant reading and writing of data between the GPU's fast internal memory and its slower external storage. In standard attention, the machine creates a massive intermediate table—the attention matrix—that grows larger than the GPU can hold, forcing it to constantly swap data back and forth. This approach revealed that 'IO-awareness,' or the explicit management of data movement, is the most effective way to scale intelligence. It proved that an algorithm can be significantly faster by doing more work—recalculating results on the fly—if it means it has to move less data. This finding suggested that the 'blueprints' of our algorithms must be designed around the physical constraints of the hardware they run on.
Tiling and Recomputation
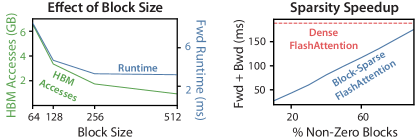
Runtime comparison showing that memory access is the primary factor affecting AI performance.
How FlashAttention achieves this efficiency lies in its use of 'tiling,' which breaks the massive attention matrix into small, bite-sized blocks that fit entirely within the GPU's fastest memory. Instead of storing the entire table, the model processes these tiles one by one, keeping track of just enough mathematical statistics to ensure the final result is exactly the same as the slower version. During the learning phase, the model even throws away parts of its intermediate calculations and simply re-computes them when needed. This revealed that the 'Memory Wall' can be bypassed by treating data as a temporary signal to be processed rather than a massive object to be stored. It proved that in the era of massive scale, computational efficiency is often a matter of minimizing the distance that data has to travel.
The Long Context Frontier
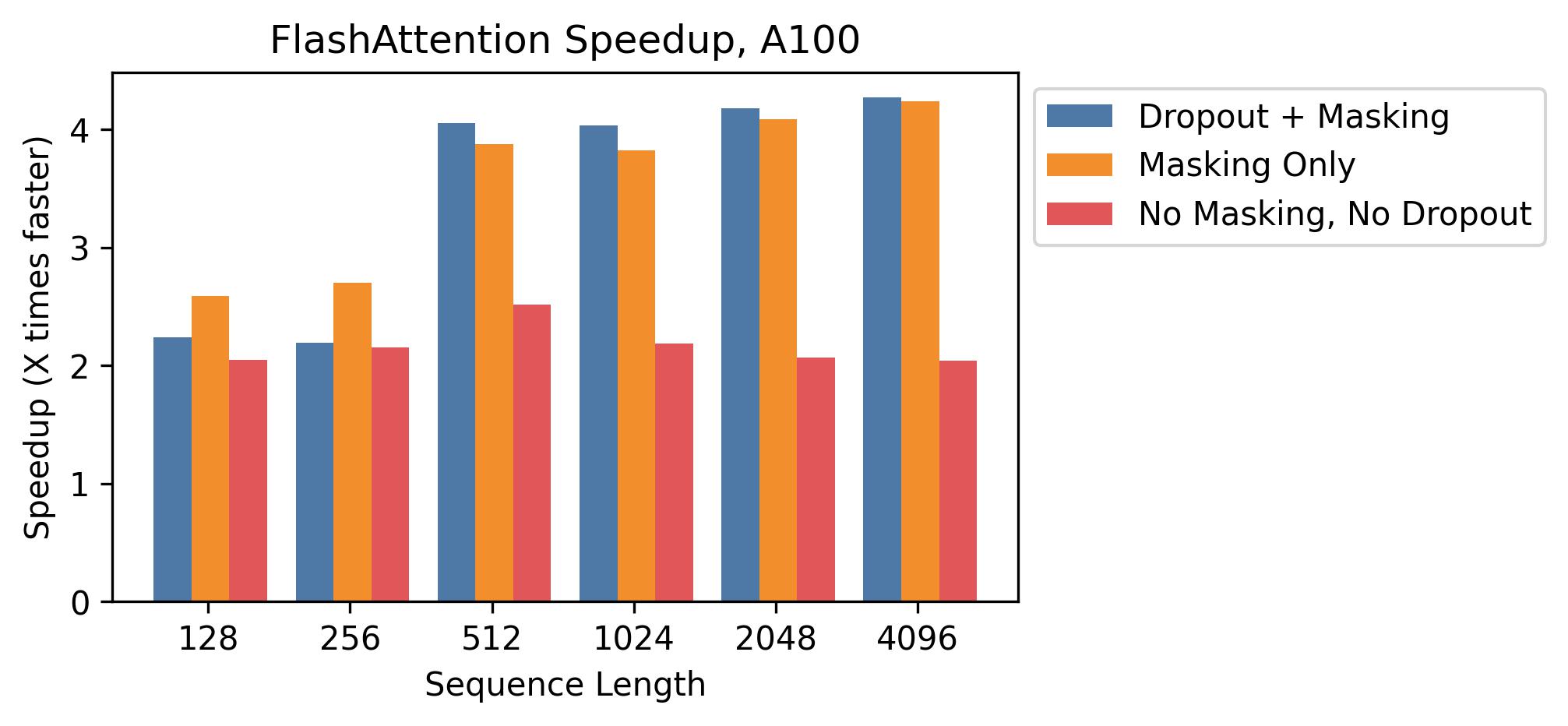
Speedup of FlashAttention over standard implementations at different sequence lengths.
The success of FlashAttention was most evident in its ability to enable models with 64,000 or even 128,000 tokens of context, a feat that was previously impossible on standard hardware. This improvement led to a 7.6x speedup in attention calculations, allowing models to process entire books or long legal documents in a single pass. This finding proved that the architecture of the Transformer is far more capable than our previous implementations suggested. It raises the question of whether the next leap in AI will come from more powerful chips or from a deeper understanding of how to manage the flow of information through the chips we already have. It suggested that the true limits of AI memory are defined more by our software's awareness of hardware than by the hardware itself.
Dive Deeper
FlashAttention Paper on arXiv
arXiv • article
Explore ResourceGitHub Implementation
GitHub • code
Explore ResourceTri Dao's Blog Post
Tri Dao • article
Explore Resource