Join the Menttor community
Access accelerated AI inference, track progress, and collaborate on roadmaps with students worldwide.
ResNet: Deep Residual Learning
He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770-778).
Read Original Paper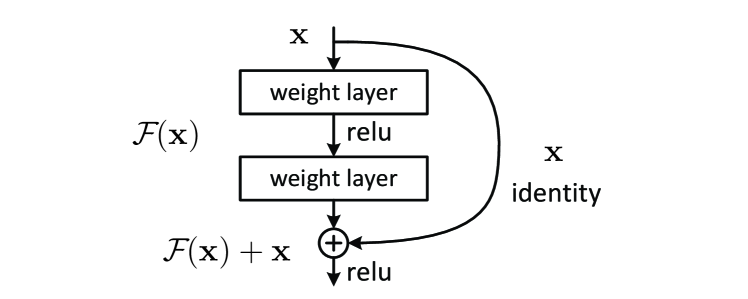
An examination of the training curves of very deep neural networks reveals a phenomenon documented by the authors of the 2015 ResNet paper. While it is intuitive to assume that adding more layers to a model should always improve performance—or at least maintain it—researchers found that after a certain point, accuracy begins to drop rapidly. This is not the result of overfitting, as the training error itself increases. The paper identified this as the 'degradation problem,' suggesting that as networks grow deeper, the optimization landscape becomes so complex that standard algorithms struggle to find even a simple identity mapping. This discovery shifted the focus of deep learning from raw model capacity to the fundamental challenge of information flow.
Residual Learning and Identity Mapping
A residual building block showing the identity shortcut connection that enables H(x) = F(x) + x.
The primary technical shift in ResNet was the introduction of residual learning, which reformulates the task of each layer. Instead of attempting to learn a direct mapping H(x), the network is designed to learn the 'residual' function F(x) = H(x) - x. This is achieved through 'shortcut connections' that simply add the input x back to the output of the weight layers. Theoretically, it should be easy for a network to learn to do nothing—an identity mapping—by setting its weights to zero. However, in standard architectures, approximating an identity mapping through multiple non-linear layers is surprisingly difficult. By making the identity mapping the default state of the network, ResNet proved that deep models are more efficient when they only need to learn the subtle deviations from their inputs rather than reconstructing the entire signal from scratch at every stage.
The Bottleneck Design for Scale
To scale the architecture to extreme depths of 101 or 152 layers, the researchers introduced a 'bottleneck' building block. Each block uses a stack of three convolutional layers: a 1x1 convolution to reduce the dimensionality of the input, a 3x3 convolution to process the features in this reduced space, and a final 1x1 convolution to restore the original dimensions. This 'sandwiched' design allows the network to maintain a manageable number of parameters and computational cost while significantly increasing its depth. This specific engineering revealed that efficiency in deep networks is achieved by carefully managing the 'width' of the representation space, forcing the model to compress and then expand information as it moves through the system. It proved that depth can be increased almost indefinitely as long as the internal representations are kept strategically narrow.
Fluidity of Gradient Flow
The reasoning behind the identity shortcut was to ensure the fluidity of gradients during backpropagation. Because the shortcut connection bypasses the weight layers, the signal from the loss function has a direct, unimpeded path to reach the earlier parts of the network. This architectural adjustment acts as a form of preconditioning, providing the optimization algorithm with a more stable and predictable starting point. This marked a shift in how depth is understood in artificial intelligence: it is not merely a measure of complexity, but a measure of how well information can pass through a system unchanged. This proved that many complex systems fail not because they lack the capacity to solve a problem, but because their internal structures are too rigid to allow the necessary signals to reach their destination.
Dive Deeper
PyTorch ResNet Tutorial
PyTorch • docs
Explore ResourceResNet Paper on arXiv
arXiv • article
Explore Resource