Join the Menttor community
Access accelerated AI inference, track progress, and collaborate on roadmaps with students worldwide.
LLaMA: Efficient Foundation Models
Touvron, H., Lavril, T., Izacard, G., Martinet, X., et al. (2023). LLaMA: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971.
Read Original Paper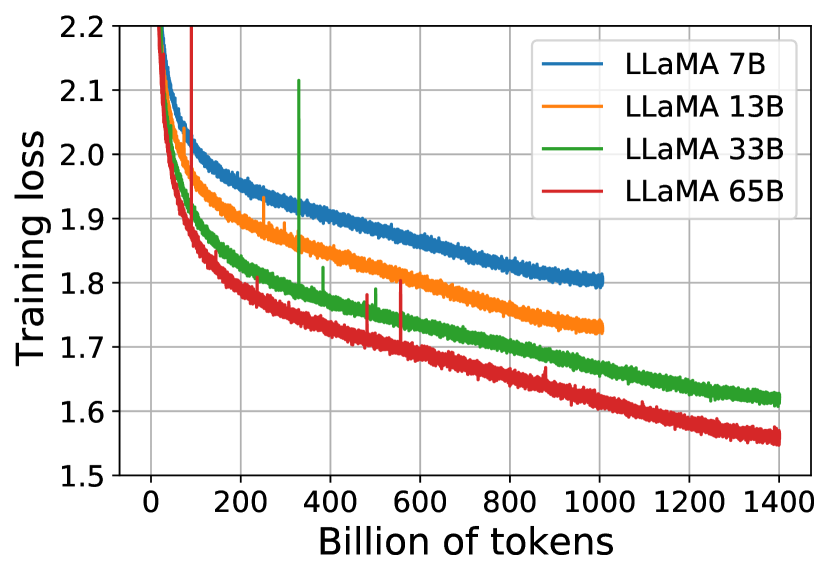
The 2023 'LLaMA' (Large Language Model Meta AI) paper challenged the prevailing belief that bigger is always better in AI. While models like GPT-3 had grown to 175 billion parameters, researchers at Meta AI focused on training smaller, more efficient models (ranging from 7B to 65B parameters) on much larger datasets. They showed that a 13B parameter model could outperform the original GPT-3 on most benchmarks, provided it was trained long enough on high-quality data. It was a shift from a 'parameter-centric' view of AI to a 'data-centric' view, prioritizing efficiency and accessibility.
The Data-Centric Shift
LLaMA performance vs. training tokens: showing the power of training smaller models longer.
The primary technical shift in LLaMA was the decision to train models on 1.4 trillion tokens, a scale that far exceeded the token-to-parameter ratios established by previous benchmarks like the Chinchilla scaling laws. While conventional wisdom suggested that a 7-billion parameter model reached its optimal training after roughly 140 billion tokens, the researchers found that performance continued to improve linearly even as the data volume reached ten times that amount. This proved that smaller models are often 'under-trained' rather than 'under-capacity.' By prioritizing the total volume and quality of the training data over the raw number of parameters, the researchers created models that were not only more capable but significantly cheaper to run at inference time. It revealed that the most efficient foundation models are those that have seen the most diverse and high-volume data during their formation.
The 1.4 Trillion Token Mixture
The quality of LLaMA's performance was directly tied to a carefully curated mixture of seven distinct datasets, with English CommonCrawl (67%) and C4 (15%) forming the core of its linguistic knowledge. The researchers applied rigorous deduplication at the line level and used a fastText linear classifier to filter out low-quality pages, ensuring that the bulk of the training material was high-signal information. This was supplemented by specialized datasets: GitHub (4.5%) provided technical reasoning and code structure, while ArXiv (2.5%) and StackExchange (2%) injected scientific rigor and problem-solving logic. Wikipedia, Books, and news articles provided the remaining breadth. This specific ratio suggested that a model's intelligence is not a monolithic property but an emergent result of balancing broad linguistic fluency with specialized technical and logical data.
Refining the Transformer Mechanism
To achieve stability at this scale, LLaMA introduced three specific architectural modifications that deviated from the original Transformer design. First, it replaced standard Layer Normalization with RMSNorm, which normalizes the input of each sub-layer rather than the output, significantly improving training stability. Second, it substituted the traditional ReLU activation with the SwiGLU function, a change that provided more expressive power in the model's feed-forward layers. Finally, it replaced absolute positional embeddings with Rotary Positional Embeddings (RoPE) at every layer, allowing the model to better capture the relative distance between tokens. These refinements were not entirely new but were systematically combined and optimized for efficient training. It revealed that significant gains in AI performance can be achieved through careful engineering and the synthesis of established best practices into a single, robust architecture.
The Open-Source Paradox
The release of LLaMA created an 'open-source paradox' where the availability of the model's weights led to a massive wave of community innovation, while simultaneously raising concerns about the control of powerful AI systems. This reveals a fundamental tension in the industry: the desire for transparency and collaboration versus the need for security and responsible deployment. It raises the question of whether the future of AI will be dominated by a few closed systems or by a vast ecosystem of open models that are continuously refined by a global community of researchers. It suggested that the true value of a foundation model lies not just in its weights, but in the ecosystem that forms around its accessibility.
Dive Deeper
Meta AI LLaMA Blog
Meta AI • article
Explore ResourceLLaMA Paper on arXiv
arXiv • article
Explore Resource