Join the Menttor community
Access accelerated AI inference, track progress, and collaborate on roadmaps with students worldwide.
RT-2: VLA Models
Brohan, A., Brown, N., Carbajal, J., Chebotar, Y., et al. (2023). RT-2: Vision-language-action models transfer web knowledge to robotic control. arXiv preprint arXiv:2307.15818.
Read Original Paper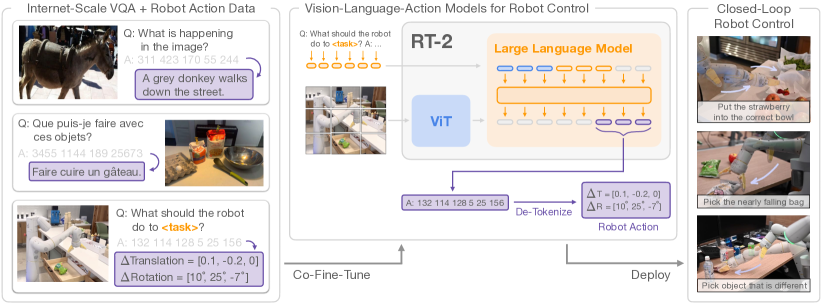
In 2023, Google DeepMind introduced 'RT-2,' a 'Vision-Language-Action' (VLA) model that directly translates visual observations and natural language instructions into robotic commands. While previous robots required separate modules for perception, reasoning, and control, RT-2 uses a single large model that has been pre-trained on billions of words and images from the internet. This allows the robot to inherit general-world knowledge—like knowing that a 'dinosaur' is a toy or that a 'healthy snack' is an apple—without ever being explicitly taught those concepts in a robotic context.
The Action as Language Shift
RT-2 architecture: translating vision and language inputs into discrete action tokens.
The core technical shift in RT-2 was the realization that robotic control can be treated as a standard language modeling problem. Instead of using a specialized output head for motor commands, the researchers represented robot actions—such as 6-DoF position and rotation—as discrete text tokens within the existing vocabulary of a Vision-Language Model (VLM). By mapping continuous physical coordinates into 256 uniform bins, the model can 'respond' to a visual observation and a text instruction with a string of tokens that represent physical movements. This unified representation allowed the robot to inherit the vast reasoning and semantic knowledge of its multi-billion parameter backbone, proving that the 'intelligence' required to solve a math problem is structurally identical to the intelligence required to manipulate a physical object.
The Co-Fine-Tuning Process
To prevent the model from forgetting its general-world knowledge while learning specific robotic skills, the researchers employed a 'co-fine-tuning' strategy. The model was trained simultaneously on two massive datasets: internet-scale vision-language data (containing 10 billion image-text pairs) and specialized robotic trajectory data. By carefully balancing the mixture weights—where robotic data made up roughly 50% to 66% of the training batches—the model learned to ground its abstract semantic understanding in physical execution. This process revealed that 'believability' in a robot is not just about mastering a narrow set of tasks, but about maintaining a broad conceptual map of the world that can be accessed during physical reasoning. It proved that robotic performance scales with the diversity of its semantic exposure, not just the volume of its physical practice.
Discretization and Cloud Inference
Because RT-2 is based on massive models like PaLM-E (55B parameters), it cannot run locally on standard robot hardware. The technical solution was to deploy the model as a cloud-based service, where the robot sends camera frames and receives actions over a high-bandwidth network. To ensure smooth movement, the system operates at a closed-loop frequency of 1–5 Hz, which is sufficient for many manipulation tasks. The 256-bin discretization of the action space provides a high enough resolution for precise movements while remaining compatible with the model's text-based output. This distributed architecture suggested that the future of robotics may lie in a 'brain-body' split, where the high-level reasoning occurs in the cloud while the low-level execution is handled by specialized on-device controllers.
Web-to-Robot Transfer
The reasoning behind RT-2 was to bridge the gap between abstract reasoning and physical execution. Because the model was pre-trained on the entire internet, it can perform 'semantic reasoning' that is impossible for models trained only on robot data. For example, if asked to 'pick up the object that is an endangered species,' RT-2 can identify a toy panda among other toys and move toward it. This revealed that the vast amount of knowledge stored in large-scale models can be 'grounded' in the physical world through a relatively small amount of robot-specific training. It proved that the bottleneck in robotics is often not the lack of data, but the lack of an interface that connects what a model 'knows' to what a robot can 'do.'
The Physicality Bottleneck
While RT-2 is highly intelligent, it still faces a 'physicality bottleneck' where its understanding of a task outpaces its fine-grained motor skills. The model may know that a 'healthy snack' is an apple, but it may still struggle with the precise dexterity required to peel it. This reveals a fundamental challenge in embodied AI: reasoning is a semantic problem, but manipulation is a physical one. It raises the question of whether the next leap in robotics will come from even larger VLAs or from a more specialized 'nervous system' that handles the sub-millisecond corrections required for high-dexterity tasks. It suggests that the path to general-purpose robots requires balancing broad world knowledge with deep, low-level physical intuition.
Dive Deeper
Google DeepMind RT-2 Blog
DeepMind • article
Explore ResourceRT-2 Paper on arXiv
arXiv • article
Explore Resource