Join the Menttor community
Access accelerated AI inference, track progress, and collaborate on roadmaps with students worldwide.
Segment Anything — SAM
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A. C., Lo, W. Y., Dollár, P., & Girshick, R. (2023). Segment Anything. arXiv:2304.02643.
Read Original Paper
The 2023 paper on 'Segment Anything' (SAM) introduced the first foundation model for computer vision that could perform zero-shot generalization across a near-infinite variety of images. Before SAM, image segmentation was a fragmented field where models were trained for specific tasks—like identifying medical tumors or detecting street signs—on specialized, relatively small datasets. The researchers at Meta AI proposed a shift: instead of training for a fixed set of categories, they built a 'promptable' model trained on over 1.1 billion masks. It was a transition from specialized computer vision to a generalized, task-agnostic system that can 'segment anything' based on a simple point, box, or text prompt, much like a human can point to an object and ask what it is.
The Promptable Shift

SAM generating three valid masks from a single ambiguous point prompt.
The fundamental technical contribution of the SAM project was the definition of the 'promptable segmentation task.' Instead of being trained to recognize a specific class like 'car' or 'person,' SAM is trained to follow an instruction—a point, a box, or a rough scribble—to find whatever object the user is interested in. This flexibility is achieved through an architecture that separates the 'seeing' from the 'deciding.' A heavyweight encoder processes the image once to understand the scene, while a lightweight decoder generates a precise mask in real-time based on the user's prompt. This proved that the most effective way to solve computer vision is not through more specific labels, but through more flexible, interactive systems. It revealed that a single model can act as a universal tool for any downstream vision task, from editing photos to analyzing medical scans.
The 1.1 Billion Mask Engine

Examples from the SA-1B dataset, containing 1.1 billion high-quality segmentation masks.
How the researchers built the massive SA-1B dataset lies in their three-stage 'data engine' that used the model to help label its own training data. They began with humans using SAM to label images, then used those results to improve the model until it could identify common objects automatically. In the final stage, the model was turned loose to generate over a billion high-quality masks across 11 million images. This approach revealed that a model can be used to scale its own intelligence by creating high-fidelity feedback loops that bypass the need for constant human supervision. It suggested that the true limit of AI is not the number of humans we have for labeling, but the efficiency of the software we use to automate the process. This proved that the most successful systems are those that can learn to assist in their own formation.
Zero-Shot Generalization
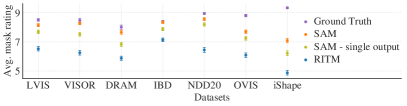
Zero-shot evaluation of SAM across 23 diverse segmentation datasets.
The success of SAM demonstrated that a model trained on a sufficiently large and diverse dataset can perform tasks it was never explicitly trained for. SAM outperformed many specialized models on diverse datasets, ranging from microscopy to underwater photography, without any additional fine-tuning. This finding revealed that 'intelligence' in vision is an emergent property of scale and diversity, rather than specific task-based optimization. It proved that a single foundation model can replace an entire ecosystem of specialized ones, showing that the real threshold for general-world understanding is the breadth of the data a model encounters during its pre-training phase. It raises the question of whether the next leap in vision will be about making models bigger or making them even more responsive to human intent.
Dive Deeper
Segment Anything Project
Meta AI • website
Explore ResourceSAM Paper on arXiv
arXiv • article
Explore Resource