Join the Menttor community
Track progress and collaborate on roadmaps with students worldwide.
Adam: Stochastic Optimization
Kingma, D. P., & Ba, J. (2014). Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.
Read Original Paper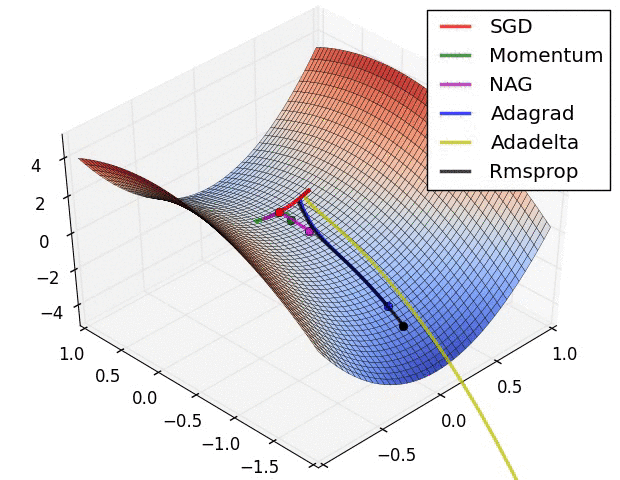
The 2014 paper 'Adam: A Method for Stochastic Optimization' by Diederik Kingma and Jimmy Ba introduced the first truly universal optimizer for deep learning. Before Adam, training large neural networks required an arduous process of manually tuning learning rates, often starting with high-level heuristics that would fail as the network became deeper or the data more complex. The researchers proposed a system that estimates the 'moments' of gradients in real-time, allowing the model to automatically adjust its speed for every single parameter. It was a shift from viewing optimization as a manual steering task to viewing it as a self-regulating physical system.
The Adaptive Moment Shift
A saddle point in a loss landscape: Adam uses momentum and adaptive scaling to navigate these complex geometries where standard SGD often stalls.
Adam resolved the instability of stochastic gradient descent by combining the benefits of momentum and adaptive scaling into a single, unified framework. By maintaining an exponentially moving average of both the gradients (the first moment) and the squared gradients (the second moment), the algorithm can smooth out the 'noise' of small batches while simultaneously scaling the updates to compensate for varying curvatures in the loss landscape. This dual-moment approach proved that the most effective way to navigate high-dimensional space is to treat the learning rate as a dynamic property of the data rather than a fixed hyperparameter. It revealed that intelligence in optimization is not about knowing the right speed, but about having the feedback loop to find it.
The Logic of Bias Correction
How Adam achieves its stability during the critical first steps of training lies in its unique bias correction mechanism. Because the moving averages are initialized at zero, they are naturally 'biased' toward the origin, which would normally result in very small initial updates. Kingma and Ba introduced a mathematical correction factor that amplifies these early signals, gradually fading away as the averages become more informed by the actual data. This engineering choice proved that the success of a complex system is often determined by how it handles its own 'cold start' period. It suggested that a robust algorithm must be aware of its own initial uncertainty and possess the mechanisms to correct for it autonomously.
The Abstraction of the Default
The success of Adam was so immediate that it quickly became the 'default' choice for almost every major deep learning architecture, from computer vision to natural language processing. This finding revealed that many disparate optimization problems actually share the same underlying statistical structure. It proved that a single, well-designed feedback loop can replace thousands of hours of manual hyperparameter tuning. It raises the question of whether there are even more fundamental 'physical laws' of optimization yet to be discovered, or if Adam represents the mathematical limit of how much a system can know about its own landscape from local gradients alone.
Dive Deeper
Adam Paper on arXiv
arXiv • article
Explore Resource