Join the Menttor community
Track progress and collaborate on roadmaps with students worldwide.
Constitutional AI
Bai, Y., Kadavath, S., Kundu, S., Askell, A., Kernion, J., ... & Kaplan, J. (2022). Constitutional AI: Harmlessness from AI Feedback. arXiv preprint arXiv:2212.08073.
Read Original Paper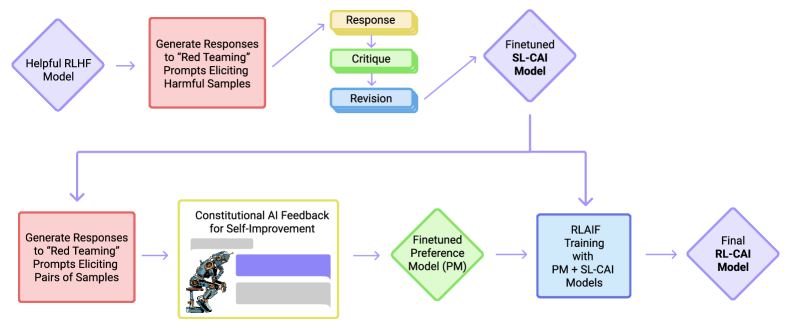
Constitutional AI introduced a method for aligning large language models that bypasses the human preference bottleneck. Traditionally, aligning a model required thousands of human rankers to manually evaluate pairs of model outputs—a process that is expensive, difficult to scale, and often reflects the inconsistent biases of the labelers. Researchers at Anthropic proposed a shift toward Reinforcement Learning from AI Feedback (RLAIF), where a model is guided by a fixed, transparent set of principles called a 'Constitution.' It was a move from crowdsourced human intuition to a structured, rule-based alignment that allows a model to autonomously supervise its own behavior.
The Self-Critique and Revision Loop
The Constitutional AI pipeline: from a natural language constitution to self-supervised alignment.
The process of Constitutional AI begins with a self-supervised critique loop where the model revises its own responses to meet the standards defined in its constitution. When given a prompt that might lead to a harmful or unhelpful output, the model first generates an initial draft and then generates a natural language critique of that draft based on a specific constitutional principle. Finally, it produces a revised version that incorporates the feedback. This mechanism proved that a sufficiently capable model can recognize and correct its own deviations from a goal if it is provided with a clear logical framework. It suggested that the knowledge of how to behave 'correctly' is often already latent within the pre-trained weights, requiring only a transparent set of instructions to activate it.
Reinforcement Learning from AI Feedback
In the second stage of the pipeline, the model uses its own internal logic to generate preference labels for a larger training set. By comparing two potential responses and selecting the one that best follows the constitution, the model acts as an 'AI Feedback' agent, replacing the need for human rankers. These automated labels are then used to train a Reward Model, which guides the final reinforcement learning process via Proximal Policy Optimization (PPO). This shift revealed that alignment can be scaled as efficiently as pre-training, moving the source of truth from human opinion to a permanent, inspectable set of written principles. It proved that the most effective way to align a machine is to give it the tools to evaluate its own reasoning against a shared standard.
Transparency and Scaling Safety
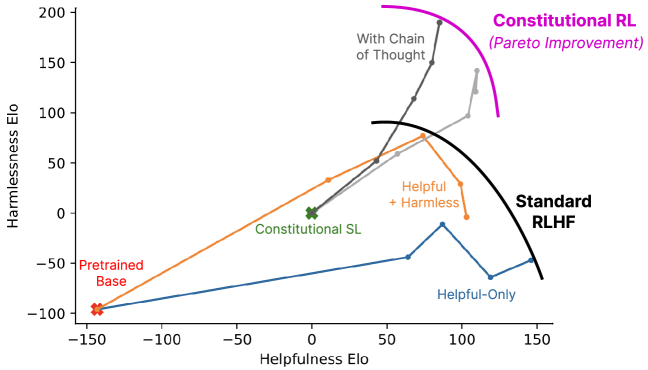
The success of Constitutional AI demonstrated that a transparent set of rules is more robust than the opaque preferences of human labelers. Because the constitution is written in natural language, it can be easily inspected, debated, and updated by human designers, providing a clear interface for controlling model behavior. This approach revealed that safety does not have to come at the expense of model performance; in many cases, RLAIF models outperformed those trained with standard RLHF on complex reasoning tasks. This finding suggested that the future of AI alignment lies in the ability to define 'algorithmic laws' that are simple enough for humans to understand but precise enough for machines to follow. It raises the question of whether we can eventually build a universal constitution that scales across all cultures and languages.
Dive Deeper
Constitutional AI (arXiv)
arXiv • article
Explore ResourceAnthropic Constitutional AI Blog
Anthropic • article
Explore Resource