Join the Menttor community
Track progress and collaborate on roadmaps with students worldwide.
LoRA: Low-Rank Adaptation
Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., ... & Chen, W. (2021). Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685.
Read Original Paper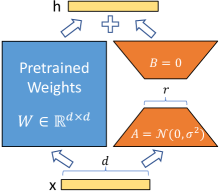
The 2021 paper 'LoRA: Low-Rank Adaptation of Large Language Models' by Hu et al. introduced a fundamental shift in how massive neural networks are adapted for specific tasks. Before this work, the status quo for fine-tuning large language models (LLMs) was defined by two equally problematic strategies: full fine-tuning, which required updating and storing hundreds of billions of parameters for every downstream application, and the use of 'adapter' layers, which inserted extra modules into the network's architecture. While full fine-tuning was computationally prohibitive and a storage nightmare for models like GPT-3, adapter layers introduced significant inference latency by increasing the depth of the model's sequential processing. This created a perceived bottleneck where researchers had to choose between the high fidelity of a fully updated model and the efficiency of a partially frozen one, often compromising on the speed and scalability of their production systems.
Low-Rank Weight Updates
LoRA reparameterizes weight updates by freezing the original weights and only training two small matrices, A and B, which are then combined for inference.
LoRA introduced a parameter-efficient method for adapting massive neural networks by reparameterization weight updates as low-rank decompositions. Instead of updating the entire pre-trained weight matrix, the researchers represented the change in weights as the product of two much smaller matrices, A and B, which capture the task-specific signal within a fraction of the total parameter count. By freezing the original base model and only training these tiny, low-rank matrices, the memory requirements for fine-tuning are dramatically reduced while maintaining zero additional inference latency through the linear merging of weights. This mechanism proved that the adaptation of a large model is not a process of re-architecting its entire knowledge base, but a surgical steering of the specific, low-dimensional directions that are already present within its pre-trained weight space.
The Low Intrinsic Dimension
The abstraction enabled by this discovery was the validation of the 'Low Intrinsic Dimension' hypothesis, which suggests that the change in a model's weights during fine-tuning has a very low intrinsic rank. The researchers found that for massive models like GPT-3, a rank as low as one or two was often sufficient to capture the necessary task-specific information, allowing for performance comparable to full fine-tuning with 10,000 times fewer parameters. This finding demonstrated that large models are heavily over-parameterized and that adaptation is less about creating new capabilities from scratch and more about amplifying the directions that are already present in the pre-trained weights. It suggested that the true intelligence of these systems is a distributed, low-dimensional signal that can be steered with extreme precision through the manipulation of a tiny fraction of its total capacity.
Zero Inference Latency
A final technical detail is the elimination of inference latency through the linear combination of weights. Because the low-rank update is represented as a simple addition to the original weight matrix, the product of the A and B matrices can be pre-computed and merged directly into the model's weights before deployment. This ensures that the adapted model maintains the exact same architecture and parameter count as the original, allowing for real-time inference with no additional computational overhead. Despite its efficiency, LoRA’s reliance on low-rank updates assumes that the target task resides in the same low-dimensional subspace as the pre-trained model’s knowledge. This suggests that LoRA might struggle with tasks that require radical departures from the model's existing world model. The boundary between weight-space steering and the necessity of full re-architecting for novel capabilities marks a significant unknown in the future of model adaptation.
Dive Deeper
LoRA Paper (arXiv)
arXiv • article
Explore ResourceFine-tuning with LoRA (Blog)
Hugging Face • article
Explore Resource