Join the Menttor community
Track progress and collaborate on roadmaps with students worldwide.
Transformer-XL: Extra Long Context
Dai, Z., Yang, Z., Yang, Y., Carbonell, J., Le, Q. V., & Salakhutdinov, R. (2019). Transformer-xl: Attentive language models beyond a fixed-length context. arXiv preprint arXiv:1901.02860.
Read Original Paper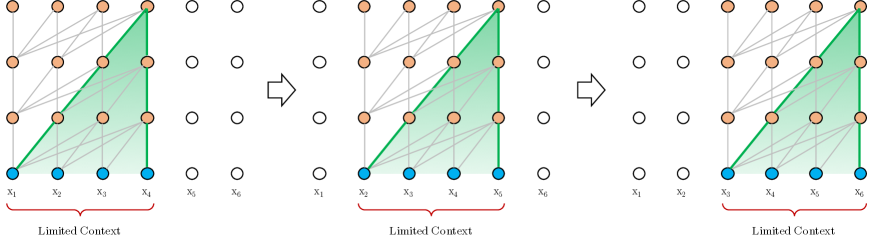
For a long time, the Transformer architecture operated within a self-imposed prison of fixed-length segments. While the attention mechanism was a leap over the vanishing gradients of RNNs, it remained tethered to a rigid window, forcing the model to process text in isolated chunks that ignored the semantic flow of what came before. This created a phenomenon known as context fragmentation, where the model, blind to the preceding segment, struggled to predict the first few tokens of a new block simply because it lacked the necessary history. It was a Newtonian approach to a quantum problem, treating language as a series of discrete events rather than a continuous stream of thought, effectively capping the model's 'intelligence' at the length of its training window.
The Segment-Level Recurrence Shift
Transformer-XL (right) vs. vanilla Transformer baseline (left) illustrating the extended dependency reach.
The shift introduced by Transformer-XL is fundamentally about memory and the reuse of state. Instead of discarding the hidden layers of a previous segment, the architecture caches them, allowing the current segment to look back at the past as an extended context. This segment-level recurrence doesn't just extend the reach of the model; it changes the very nature of how information propagates. By treating the previous segment’s hidden states as a fixed memory bank, the network can capture dependencies that are significantly longer than its training window, effectively bridging the gaps that previously led to fragmented understanding. It is an intuitive 'how' that mimics human reading, for we don't forget the previous page just because we've turned to the next one.
Relative Positional Encoding

Visualization of relative attention over previous tokens, showing how the model prioritizes temporal distance.
Simply caching states isn't enough because the model’s sense of where things are, specifically its positional encoding, was originally tied to absolute indices. If the first word of every segment is labeled as position one, the model loses the ability to distinguish between a word that appeared ten tokens ago and one that appeared a hundred tokens ago across a segment boundary. Transformer-XL solves this through a novel relative positional encoding scheme. By focusing on the distance between tokens rather than their absolute coordinates, the model maintains temporal coherence even as it reuses information from the past. This shift allows the attention mechanism to generalize to sequences much longer than those seen during training, providing a stable temporal bias that doesn't break when the context expands.
The Implication of Memory
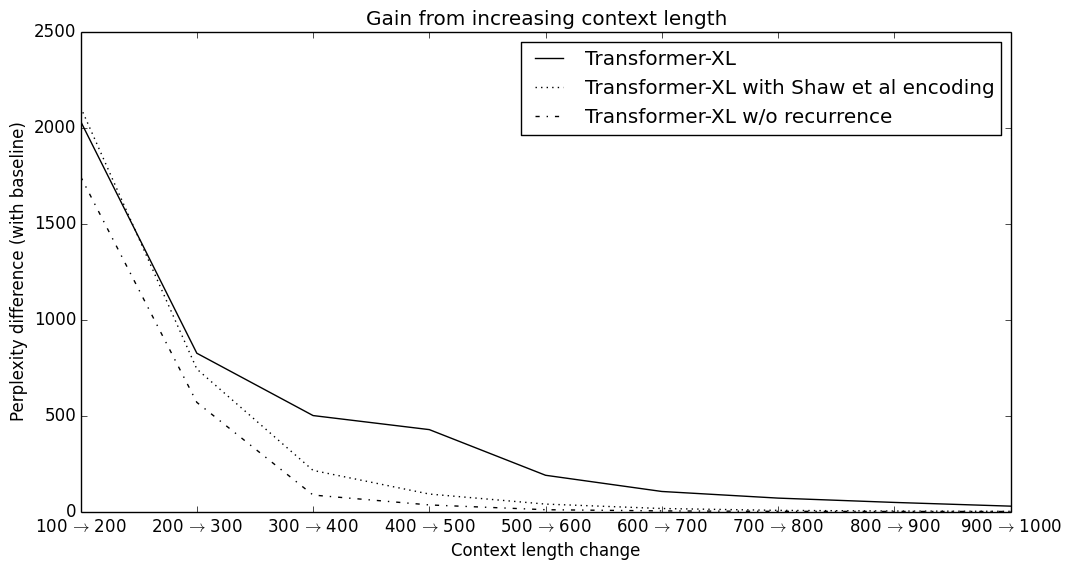
The implications of this architecture are staggering, with evaluation speeds increasing by over 1,800 times and the ability to model dependencies nearly five times longer than vanilla Transformers. It suggests that the bottleneck in language modeling wasn't necessarily the attention mechanism itself, but how we managed the flow of time and memory within it. While Transformer-XL can now generate coherent articles spanning thousands of tokens, it leaves us with an open question about the limits of this recurrence. As we move toward models that can remember across even vaster horizons, we must wonder if the next leap lies in more efficient memory compression or in a fundamental rethinking of how machines perceive the passage of narrative time.
Dive Deeper
Transformer-XL Paper (arXiv)
arXiv • article
Explore ResourceGoogle AI Blog: Transformer-XL
Google AI • article
Explore Resource