Join the Menttor community
Track progress and collaborate on roadmaps with students worldwide.
Scaling Laws for Neural Language Models
Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., ... & Amodei, D. (2020). Scaling laws for neural language models. arXiv preprint arXiv:2001.08361.
Read Original Paper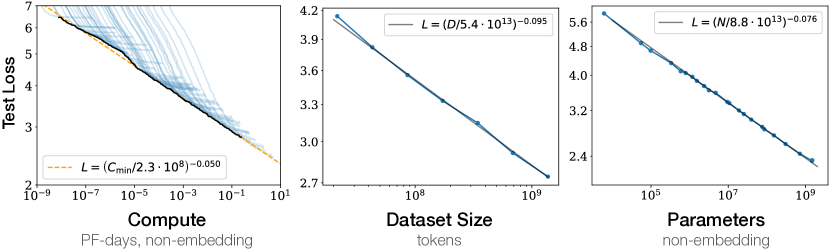
The 2020 paper 'Scaling Laws for Neural Language Models' by Kaplan et al. marks a definitive shift in the field of deep learning, transitioning the development of large-scale models from heuristic experimentation to a predictable engineering discipline. Before this work, the prevailing status quo was defined by an obsession with architectural hyperparameters, where researchers spent significant effort tuning depth-to-width ratios, the number of attention heads, and feed-forward dimensions under the assumption that these were the primary drivers of performance. The standard practice was to train relatively small models to full convergence, a process that prioritized squeezing the last bit of utility out of limited capacity rather than scaling the underlying system. This approach was governed by a belief that increasing model size required a massive, proportional increase in data to avoid immediate overfitting, creating a perceived bottleneck that constrained the ambition of neural network design.
The Power-Law Relationship
Language modeling performance improves smoothly as we increase the model size, dataset size, and compute. Empirical performance has a power-law relationship with each individual factor when not bottlenecked by the other two.
The fundamental technical discovery was that the cross-entropy loss of a language model follows a precise, predictable power-law relationship with three primary variables: the number of non-embedding parameters, the size of the dataset, and the total amount of compute used for training. By analyzing these relationships over seven orders of magnitude, the researchers found that performance improves smoothly as any of these factors are increased, provided the others are not bottlenecked. A critical nuance in this finding was the exclusion of embedding parameters, which revealed that the core Transformer blocks obey a universal scaling law that remains stable across a vast range of scales. This proved that language modeling performance is not a chaotic variable of specific architectural choices, but a structural property of scale itself. It revealed that the 'meaning' captured by a model is a function of its total capacity to process information rather than the specific way that capacity is partitioned.
The Compute-Efficient Frontier
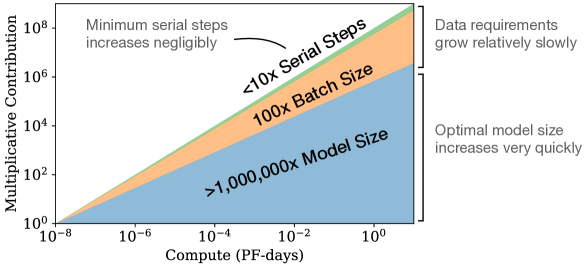
For optimally compute-efficient training, most of the increase in compute should go towards increased model size, with relatively small increases in data and serial training time.
This shift in understanding enabled a new abstraction for reasoning about the global properties of neural networks, often described as a form of thermodynamics for language models. The discovery of the compute-efficient frontier demonstrated that for a fixed budget, the most effective path is to train significantly larger models on relatively modest amounts of data and stop training well before full convergence. This contradicted the earlier assumption that data was the primary constraint, showing instead that larger models are fundamentally more sample-efficient and can reach a lower loss using fewer total tokens than their smaller counterparts. By focusing on the 'sweet spot' defined by the critical batch size, which itself grows as a power of the loss, researchers could optimize the tradeoff between wall-clock time and total compute. It suggested that the most powerful architectures are those that prioritize raw capacity over the efficiency of individual training steps, allowing for a level of predictability that makes the behavior of massive models visible through small-scale experiments.
Architectural Independence
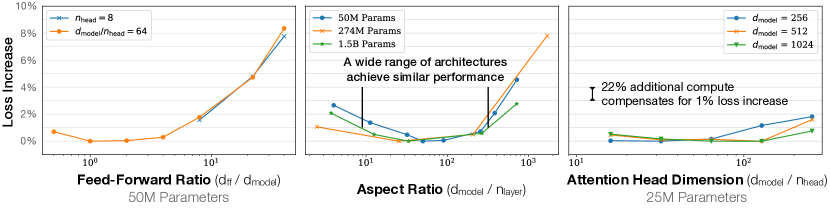
When excluding embedding parameters, the performance of models with different depths converges to a single trend, showing that performance depends primarily on parameter count rather than model shape.
Perhaps the most surprising technical detail was the near-total independence of performance from specific architectural 'shapes' like depth or width. Within reasonable limits, a shallow and wide model performs almost identically to a deep and narrow one, provided they share the same total parameter count. This finding dismantled the idea that there is a 'perfect' ratio of layers to hidden dimensions that must be discovered through exhaustive search. Despite its predictive power, the researchers noted that these laws are highly sensitive to the precise measurement of exponents and may eventually break down as models reach extreme scales where the underlying data distribution becomes the primary bottleneck. The existence of a fundamental limit to the information density of language remains an open problem, as it is unclear if any amount of additional compute or parameters can eventually resolve the inherent noise in human expression.
Dive Deeper
OpenAI Blog: Scaling Laws
OpenAI • article
Explore ResourceScaling Laws Paper (arXiv)
arXiv • article
Explore Resource