Join the Menttor community
Track progress and collaborate on roadmaps with students worldwide.
Dropout: Stochastic Regularization
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., & Salakhutdinov, R. (2014). Dropout: a simple way to prevent neural networks from overfitting. The journal of machine learning research, 15(1), 1929-1958. [First presented in 2012]
Read Original Paper
The 2012 paper 'Dropout: A Simple Way to Prevent Neural Networks from Overfitting' by Hinton et al. introduced a fundamental shift in how high-capacity neural networks are regularized. Before this work, the primary constraint on deep learning was a significant generalization gap, where large feedforward models would easily achieve near-perfect accuracy on training data while remaining remarkably fragile when presented with unseen examples. This status quo was defined by the problem of 'complex co-adaptations,' where individual neurons would become overly specialized to the specific noise and quirks of a training set, relying on the presence of other specific neurons to correct their errors. The resulting feature detectors were often noisy and uninterpretable, representing a failure of the network to learn the underlying distribution of the data in a robust, independent manner.
Stochastic Neuron Omission
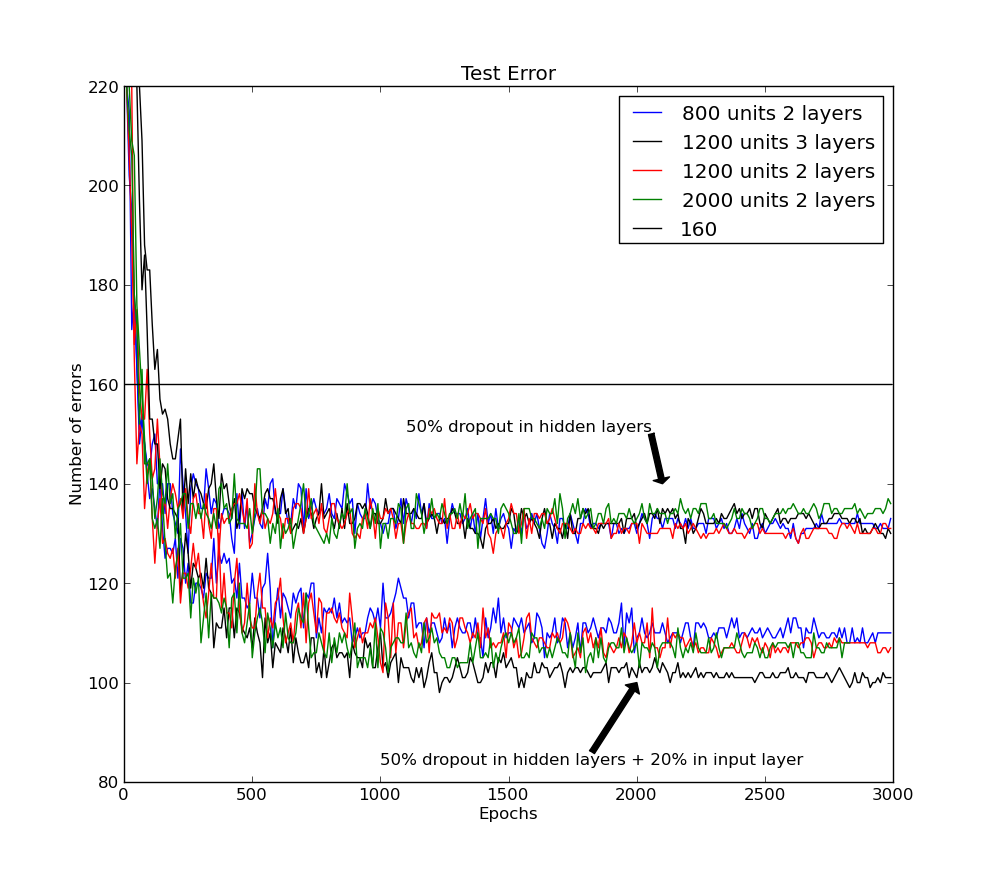
Error rate on the MNIST test set for architectures trained with dropout. The lower lines use dropout on both input and hidden layers, showing consistent improvement over standard backpropagation.
Dropout revolutionized the regularization of deep neural networks by introducing stochasticity directly into the architecture during the training process. By randomly omitting half of the hidden units for each training iteration, the researchers forced the network to operate as a different, thinned sub-architecture for every mini-batch, effectively breaking the complex co-adaptations where neurons rely on specific partners to correct their errors. This mechanism forces each individual unit to learn robust, generally helpful features that can survive in a combinatorially large variety of internal contexts. It proved that the most effective way to prevent overfitting is not through mathematical penalties like L2 regularization, but through a structural constraint that makes the system's intelligence redundant and distributed. This shift suggests that robustness is an emergent property of a system where every part is capable of contributing independently.
Breaking Co-adaptations
Feature detectors learned with dropout show cleaner, more distinct structures compared to the noisy, co-adapted features produced by standard backpropagation.
The abstraction enabled by this discovery was the realization that robust features are those that can survive in a combinatorially large variety of internal contexts. By breaking the reliance of neurons on their 'buddies,' Dropout forces the network to learn cleaner, more interpretable features, such as distinct edge detectors in the early layers of a vision model. This 'mixability' theory suggests that the intelligence of a neural network is not a monolithic signal produced by a fixed ensemble of parts, but a redundant and distributed system where each component is capable of contributing to the final output independently. It revealed that the bottleneck in generalization was often the tendency of backpropagation to find narrow, fragile paths through the weight space that only work when every part of the system is perfectly aligned.
Exponential Model Averaging
A final technical detail is the framing of Dropout as a computationally efficient approximation of Bayesian model averaging. The researchers argued that training with Dropout is equivalent to training an ensemble of $2^N$ different architectures that all share the same underlying weights, providing the benefits of a massive model ensemble for the inference cost of a single network. While Dropout effectively solves the problem of co-adaptation, it significantly increases the total time required for training, as each update only affects a fraction of the network's capacity. This suggests that the cost of robustness is a decrease in optimization efficiency. The search for a more deterministic method that achieves the same regularization benefit without the stochastic penalty of longer training cycles remains a primary challenge for architectural design.
Dive Deeper
Dropout Paper (arXiv)
arXiv • article
Explore ResourceVisualizing Dropout
Medium • article
Explore Resource