Join the Menttor community
Track progress and collaborate on roadmaps with students worldwide.
Chain of Thought Prompting
Wei, J., Wang, X., Schuurmans, D., Maeda, M., ... & Zhou, D. (2022). Chain-of-thought prompting elicits reasoning in large language models. arXiv preprint arXiv:2201.11903.
Read Original Paper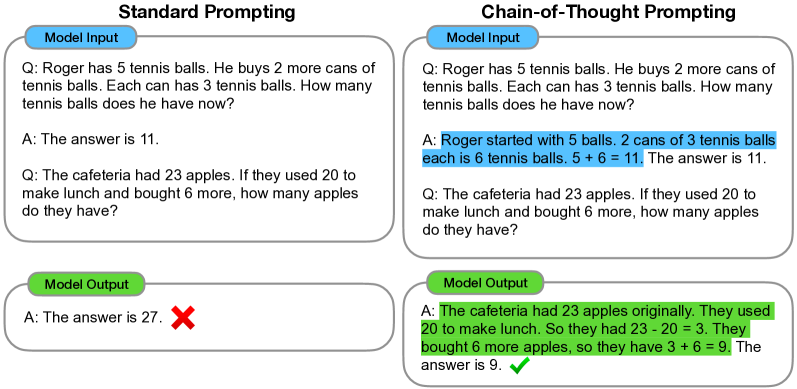
The 2022 'Chain of Thought' (CoT) paper introduced a fundamental structural shift in how large language models are prompted to solve complex problems. Before this work, standard few-shot prompting relied on simple input-output pairs, where the model was expected to map a question directly to a final answer in a single forward pass. Researchers at Google demonstrated that by providing the model with examples that include intermediate reasoning steps, the system could solve arithmetic, commonsense, and symbolic tasks that were previously far beyond its capabilities. It was a transition from viewing an LLM as a direct lookup table to viewing it as a sequential processor of logic.
The Sequential Decomposition Shift
Chain-of-thought prompting enabling models to tackle complex tasks by generating intermediate reasoning steps.
Chain of Thought prompting resolved the failure of large language models to solve multi-step problems by replacing standard input-output exemplars with triples that include an intermediate reasoning trace. In this framework, the model is shown how to break a difficult leap into a series of manageable logical deductions before arriving at the final result. This shift from direct mapping to sequential decomposition allows the model to allocate more tokens—and thus more internal computation—to the most difficult parts of a query. It revealed that the 'intelligence' of a model is not just a function of its parameters, but of the structural freedom it is given to process a thought step-by-step rather than all at once.
The Scaling Threshold
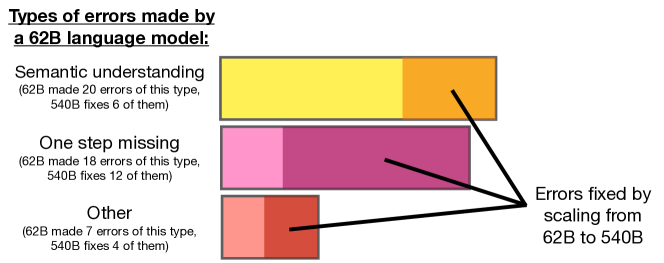
Error analysis across model scales: PaLM 540B fixes substantial portions of reasoning and semantic errors found in smaller versions.
A critical discovery of the paper was that Chain of Thought reasoning is an emergent capability that only appears when models reach a specific size threshold. While CoT often fails or even degrades performance in models with fewer than 10 billion parameters, significant gains appear once architectures reach the 100-billion parameter scale. This 'Aha Moment' revealed that as models grow, they develop a latent ability to handle logical dependencies that cannot be activated by standard prompting alone. This finding proved that the bottleneck in artificial intelligence was not always a lack of knowledge, but a failure to provide the model with the right structural interface to access the complex patterns it has already learned.
Generality and Interpretability
The success of CoT demonstrated that human-like reasoning can be elicited across diverse domains—from mathematical word problems to commonsense ethics—using only natural language as the medium. Beyond performance, this approach introduced a new level of interpretability into the 'black box' of neural networks, as the generated chain provides a window into where a logical error occurred. This shift toward inspectable reasoning traces proved that the most effective way to align a machine's logic with our own is to treat language as a shared space for problem-solving. It raises the question of whether the future of reasoning lies in larger models or in more sophisticated prompting architectures that can better structure the flow of these intermediate thoughts.
Dive Deeper
Chain of Thought Paper (arXiv)
arXiv • article
Explore ResourceGoogle Research Blog: CoT
Google Research • article
Explore Resource