Join the Menttor community
Track progress and collaborate on roadmaps with students worldwide.
KAN: Kolmogorov-Arnold Networks
Liu, Z., Wang, Y., Vaidya, S., ... & Tegmark, M. (2024). KAN: Kolmogorov-Arnold Networks. arXiv preprint arXiv:2404.19756.
Read Original Paper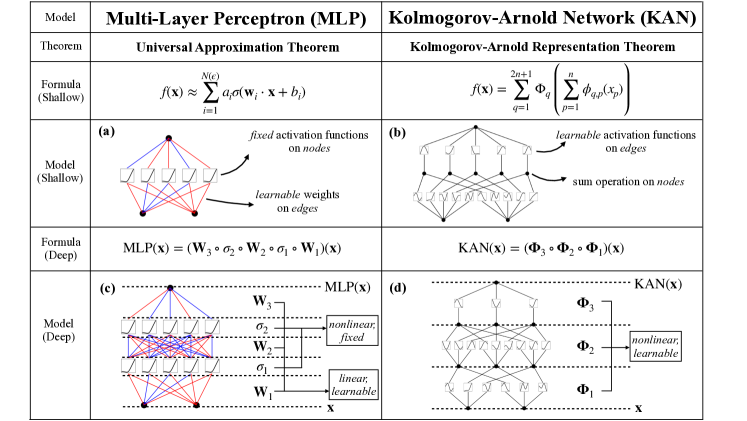
The structural foundation of deep learning has been dominated for decades by the Multi-Layer Perceptron (MLP), which interleaves linear weight matrices with fixed non-linear activation functions situated at the nodes. This design choice creates a fundamental limitation where the network's expressive power is tied to the width and depth of its static nodes, while the internal degrees of freedom of the activations themselves remain unused. Consequently, MLPs often require a massive expansion in parameter count to approximate complex functions, leading to the "curse of dimensionality" and a lack of transparency in the resulting high-dimensional representations. The proposal of Kolmogorov-Arnold Networks (KANs) challenges this status quo by fundamentally reorganizing the computational graph based on a different mathematical premise.
Learnable Activations on Edges
The structural shift: moving activation functions from nodes (MLPs) to edges (KANs).
Kolmogorov-Arnold Networks rethink the structure of a neural network by shifting the learnable parameters from the nodes to the edges. Grounded in the Kolmogorov-Arnold representation theorem, a KAN replaces every traditional "weight" with a learnable univariate function, while the nodes perform a simple summation of the incoming signals. These activation functions are parameterized using B-splines, which are linear combinations of local basis functions. This adjustment allows for "grid extension," where the granularity of the spline grids can be increased to improve accuracy without requiring the model to be retrained from scratch. This finding revealed that capture complex non-linearities can be achieved with orders of magnitude fewer parameters than an MLP would require, simply by optimizing the internal flexibility of the edges.
Interpretability and Continual Learning
Beyond parameter efficiency, KANs provide a unique path toward scientific discovery through "symbolification." Because the activation functions on the edges are univariate, they can be visualized and manually fitted to symbolic forms like sines, exponentials, or logarithms, allowing the network to reveal the underlying mathematical laws of a dataset. Furthermore, KANs naturally avoid the problem of catastrophic forgetting in continual learning. This advantage is a result of the local support of the B-spline basis functions; updating a specific region of the input space only affects the local spline coefficients for that region, preserving the knowledge stored in other parts of the network. This inherent locality suggests that the path to general intelligence may lie in architectures that can adapt to new information without erasing the structural patterns of the past.
Dive Deeper
KAN Paper on arXiv
arXiv • article
Explore ResourceOfficial KAN Implementation
GitHub • code
Explore ResourceKolmogorov-Arnold Networks Blog Post
MIT • article
Explore Resource