Join the Menttor community
Track progress and collaborate on roadmaps with students worldwide.
DeepSeek R1: Reasoning
DeepSeek-AI. (2025). DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv preprint arXiv:2501.12948.
Read Original Paper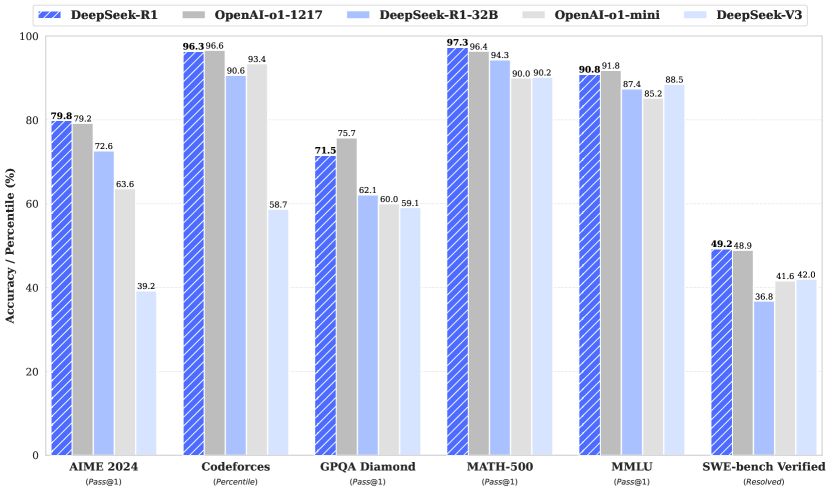
The 2025 paper 'DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning' represents a fundamental shift in the development of reasoning-oriented models. Before this breakthrough, high-level reasoning was largely viewed as a byproduct of massive Supervised Fine-Tuning (SFT), where models were explicitly taught 'Chain of Thought' patterns through vast sets of human-annotated examples. While inference-time scaling had demonstrated the power of extended computation, the industry remained tethered to the assumption that a model must first be shown how to reason before any reinforcement learning could effectively take place. This status quo relied on the quality and quantity of human demonstrations, creating a bottleneck that limited the model's ability to discover strategies beyond those provided in its training data.
Pure Reinforcement Learning
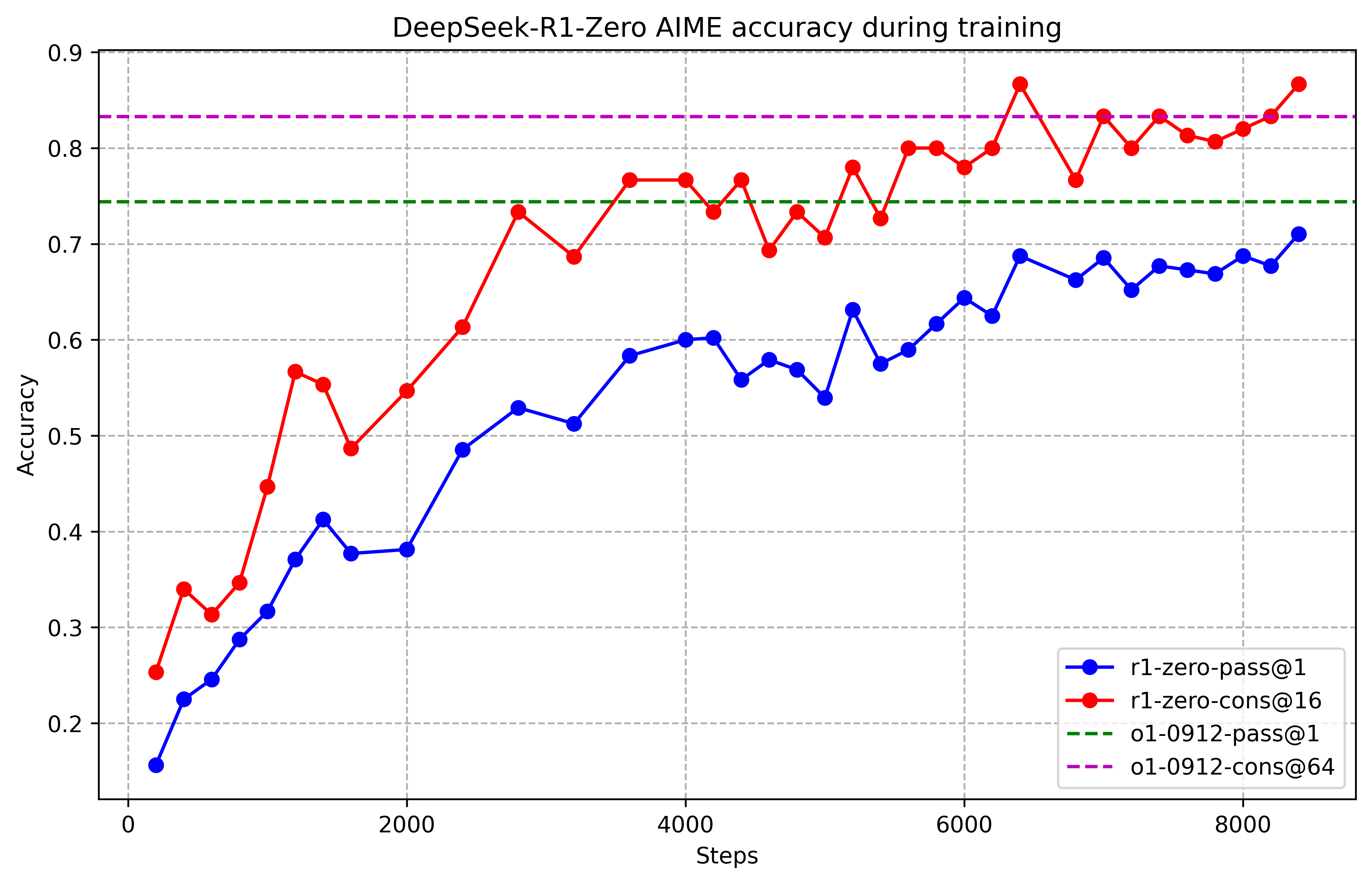
Performance of DeepSeek-R1-Zero during RL training, showing the smooth emergence of reasoning capability over time.
DeepSeek-R1-Zero disrupts the standard development pipeline by applying Reinforcement Learning (RL) directly to a base model without any preliminary supervised steps. The architectural backbone of this approach is Group Relative Policy Optimization (GRPO), an algorithm that eliminates the need for a separate 'critic' model by calculating advantages relative to a group of sampled outputs for each query. This reduction in computational overhead allowed for the scaling of RL to a level where complex reasoning behaviors emerged purely from rule-based rewards tied to accuracy and formatting. The discovery that a model can develop sophisticated logic without human demonstrations suggests that the 'reasoning engine' of a neural network is a latent property that can be unlocked through consistent, objective feedback loops rather than just imitation.
The Emergence of Self-Correction
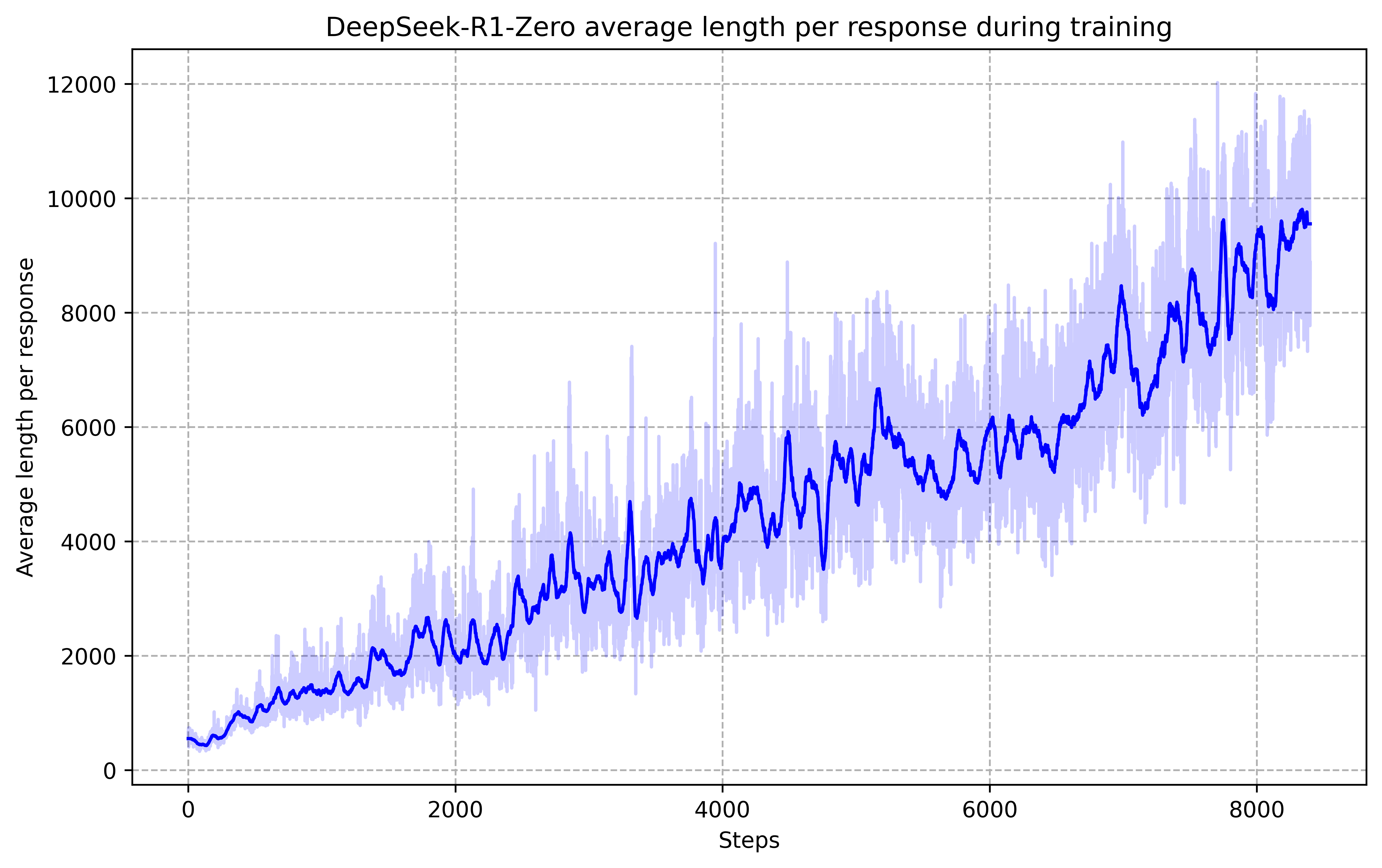
The average response length increases naturally during the RL process as the model learns to solve reasoning tasks with more extensive thinking time.
During the training of DeepSeek-R1-Zero, researchers observed the spontaneous emergence of what they termed an 'Aha Moment,' where the model autonomously learned to pause and re-evaluate its initial logic. When faced with a complex problem, the model began to flag its own potential errors—often using internal monologue to explicitly check its work—and pivot to more effective strategies. This behavior was not programmed into the system; it evolved as a self-optimized method for maximizing rewards by allocating more 'thinking time' to difficult steps. It revealed that the concept of 'deliberation' in an artificial system is an emergent property of the optimization landscape, suggesting that the most powerful reasoning models are those that are allowed to define their own internal pathways toward a solution.
Distillation and Bottlenecks
The ability to transfer these reasoning patterns from massive RL models to smaller dense models proved that reasoning logic can be compressed and distilled. A 32B model distilled from DeepSeek-R1's reasoning samples significantly outperforms same-sized models trained via direct reinforcement learning, indicating that the discovered logic is a more effective training signal than raw reward feedback. However, this approach maintains significant bottlenecks, including a high sensitivity to prompt formatting and a tendency for the model to default to specific languages during its internal thought process regardless of the user's query language. The slower progress in domains like software engineering, where asynchronous evaluations are computationally expensive, highlights the remaining gaps between abstract mathematical logic and practical system interaction.
Dive Deeper
DeepSeek R1 Paper (arXiv)
arXiv • article
Explore ResourceDeepSeek Official Blog
DeepSeek • article
Explore Resource